
这是一个创建于 54 天前的主题,其中的信息可能已经有所发展或是发生改变。

前言
前几天,我在我的 pve 服务器上新装了一台虚拟机,启动后,发现设备的总内存占用比平常高,检查了下进程列表,发现是跑网站的那台虚拟机内存泄露了,已经连续 8 天内存占用超过 80%了。
这样下去可不行,为了防止类似问题再发生,我决定在 PVE 上实现一套告警服务,实时监控每台虚拟机的运行状况,一旦发现异常,就通过邮件提醒我。
本文就跟大家分享下我的解决方案,欢迎各位感兴趣的开发者阅读本文。
方案设计
pve 本身只提供了一些基础的 API ,会返回一些数据。因此我们需要借助第三方的工具来实现,我调研到的方案为:
- prometheus-pve-exporter 用于将 PVE 的性能和状态指标暴露出来。
- Prometheus 用于采集和存储监控数据,它会采集prometheus-pve-exporter提供的数据进行监控。
- Alertmanager 用于处理 Prometheus触发的告警并发送邮件通知。
- Grafana 用于可视化监控数据,它会读取prometheus-pve-exporter返回的数据,以图表的形式展现出来。
环境信息
本章节,我将列举当前设备的环境信息。
- pve
7.4 - prometheus-pve-exporter
3.4.5 - Prometheus
2.55.0 - Alertmanager
0.25..0 - Grafana
11.3.0
最终效果
给大家看一下我这套服务最终搭建好后的样子。
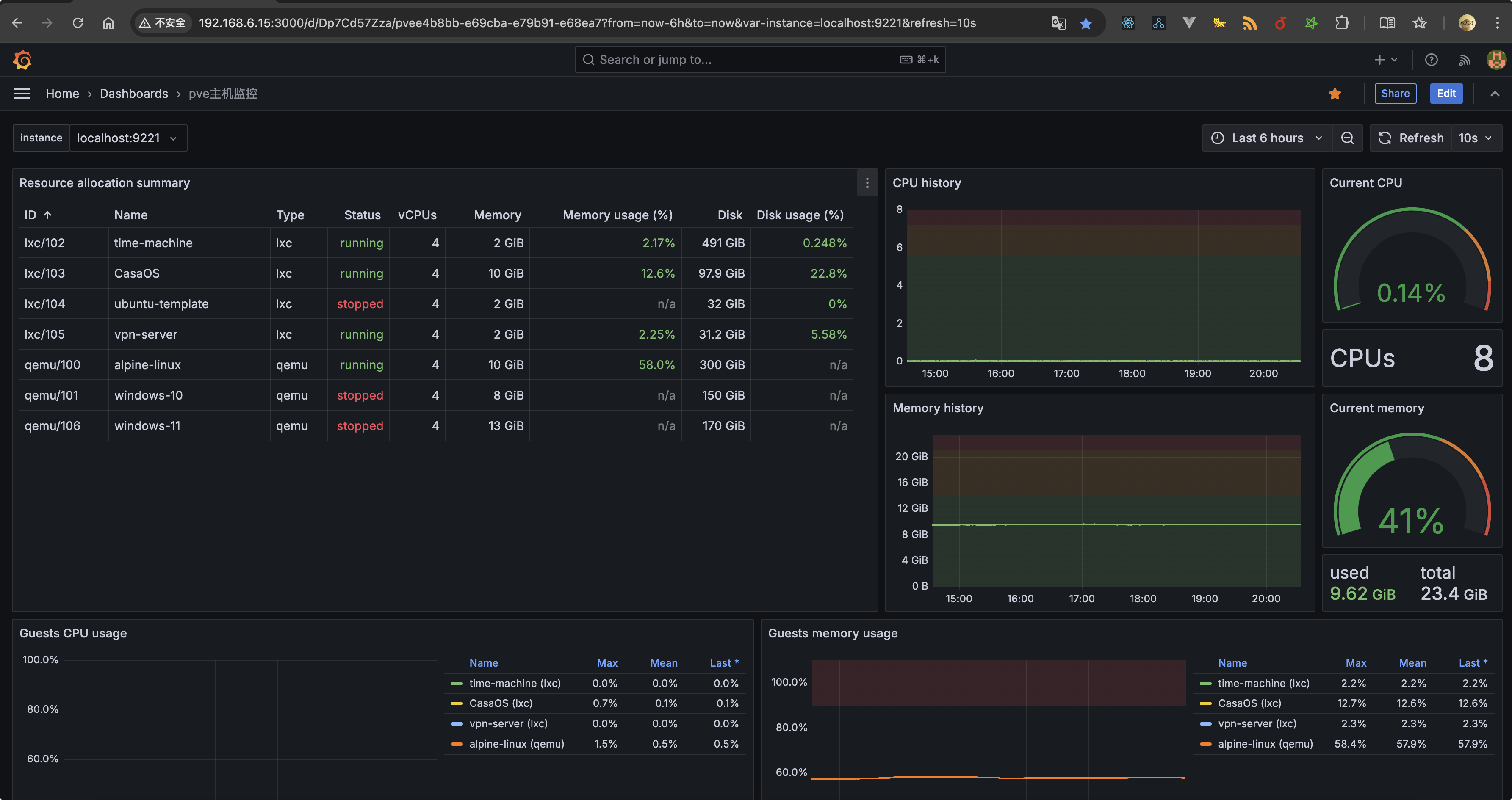
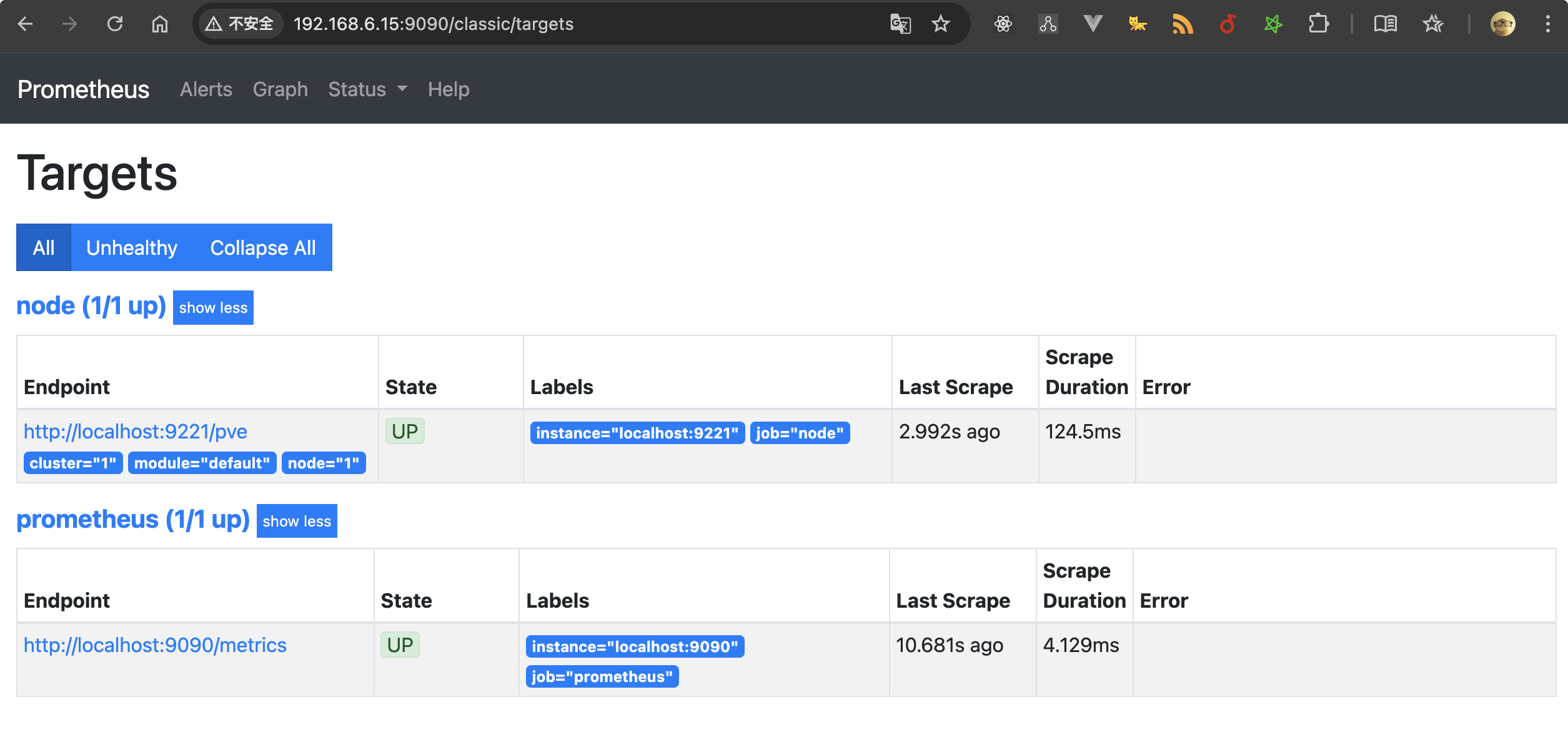
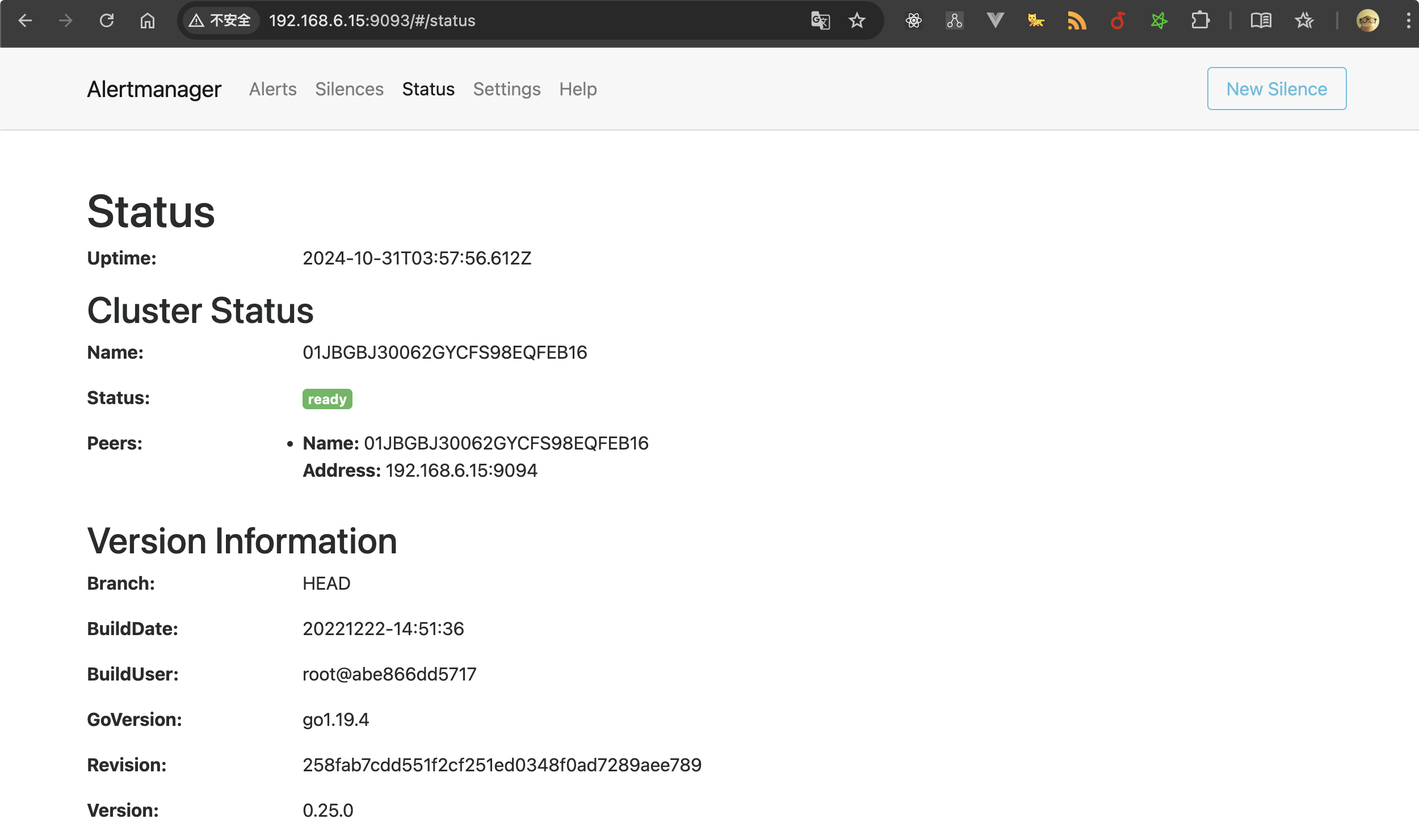
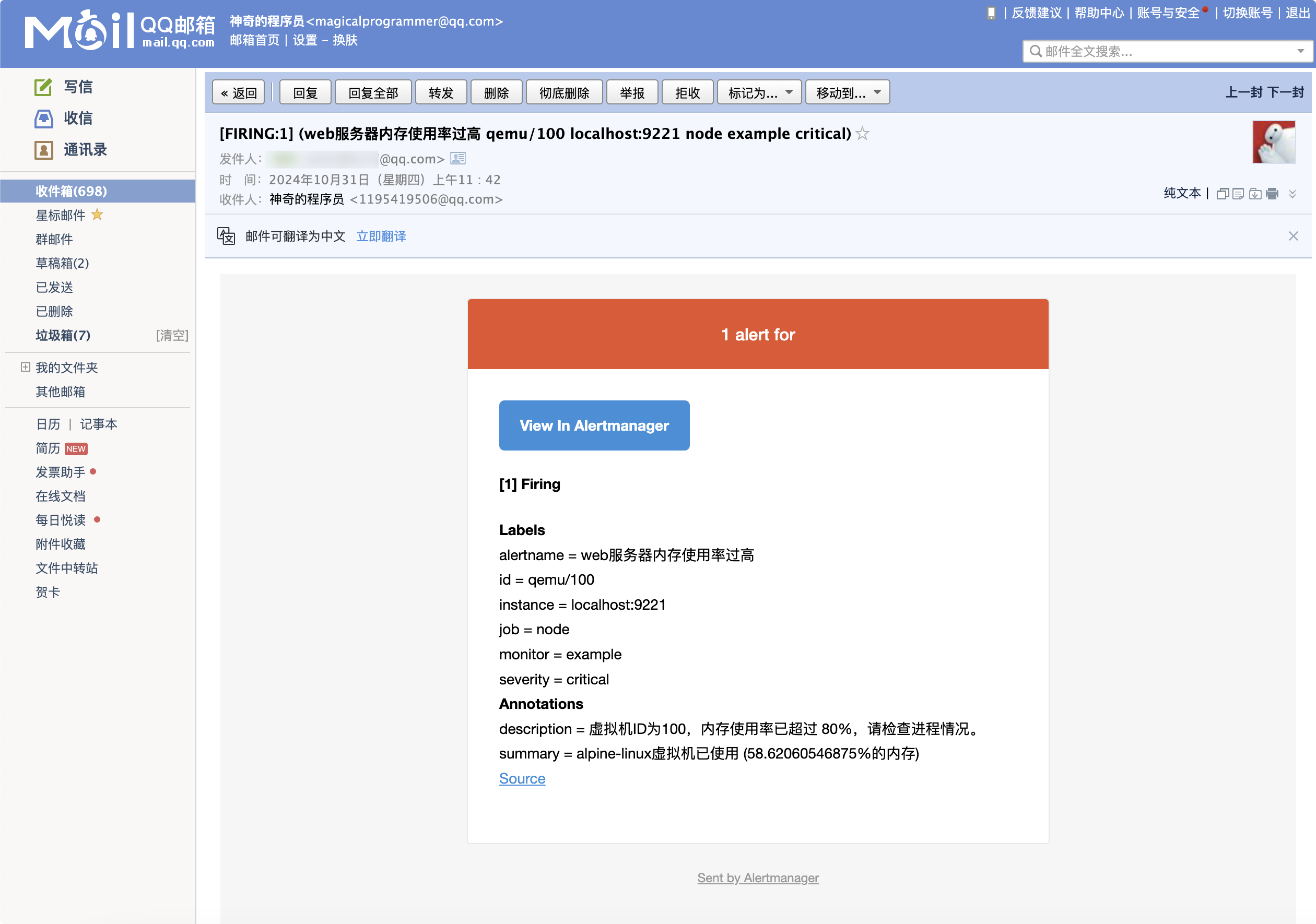
实现过程
本章节,我将分享此方案的具体实现过程。
配置 prometheus-pve-exporter
该工具会将 PVE 的性能和状态指标暴露给 Prometheus 进行监控,通过 ssh 连接 pve 后台后,执行下述命令
- 更新软件包,安装 python3 环境
apt update && apt upgrade -y
apt install python3 python3-pip -y
- 安装
prometheus-pve-exporter
pip3 install prometheus-pve-exporter
安装成功后,文件会存储在/usr/local/bin/pve_exporter这个位置。
创建 PVE 监控用户
进入 PVE 的 Web 界面,创建一个用户专用于 Prometheus 监控:
- 数据中心->用户->添加,用户名填写monitoring,领域选择:
Proxmox VE authentication server,设置密码

随后,为用户设置权限。
- 数据中心 - 权限 - 添加 - 用户权限
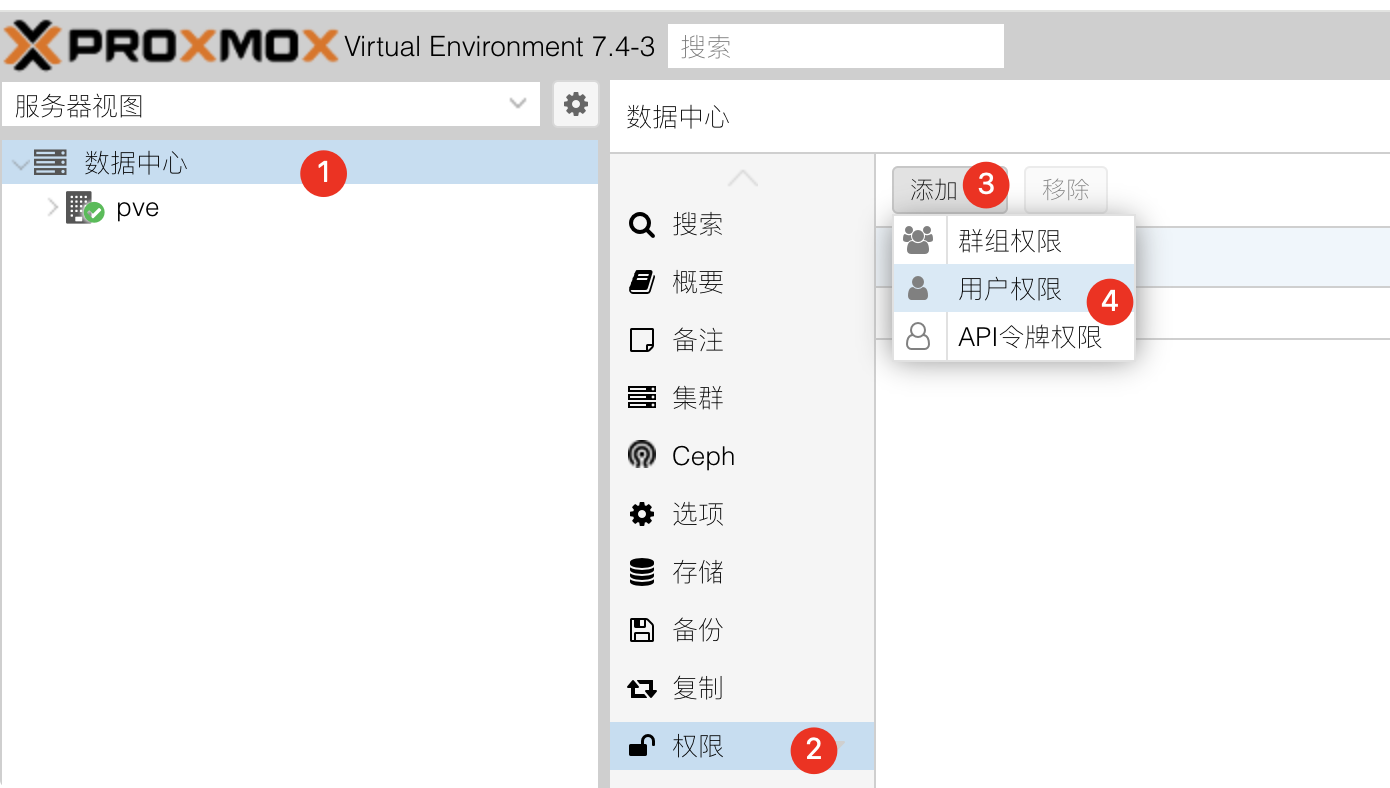
- 路径选择
/,用户选择你刚才创建的,权限选择PVEAuditor
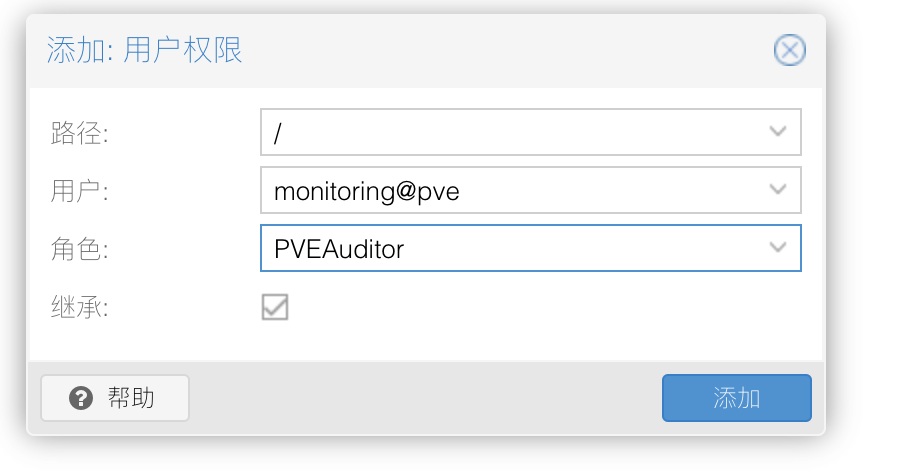
注意⚠️:此处的用户名你可以随意命名,这一步的用户名与密码会在后续的配置中用到。
创建配置文件
选择你熟悉的编辑器来创建,我这里使用的是nvim
nvim /etc/prometheus-pve-exporter/pve.yml
编辑文件,添加下述内容
default:
user: monitoring@pve
password: 你刚才设置的密码
# Optional: set to false to skip SSL/TLS verification
verify_ssl: false
注意⚠️:此处的 user 就是你刚才创建的那个用户名,但是要加上 @pve ,因为它隶属于 pve 群组下。
创建 Systemd 服务
为 prometheus-pve-exporter 创建一个 Systemd 服务,便于管理(启动、停止、重启、开机自启),同样的用你熟悉的编辑器来创建即可。
nvim /etc/systemd/system/prometheus-pve-exporter.service
添加下述内容:
[Unit]
Description=Proxmox Exporter
After=network.target
[Service]
ExecStart=/usr/local/bin/pve_exporter --config.file /etc/prometheus-pve-exporter/pve.yml --web.listen-address=:9221
Restart=always
[Install]
WantedBy=multi-user.target
保存并关闭文件,然后执行以下命令启动服务:
systemctl daemon-reload
systemctl start prometheus-pve-exporter
systemctl enable prometheus-pve-exporter
验证 Exporter 是否运行
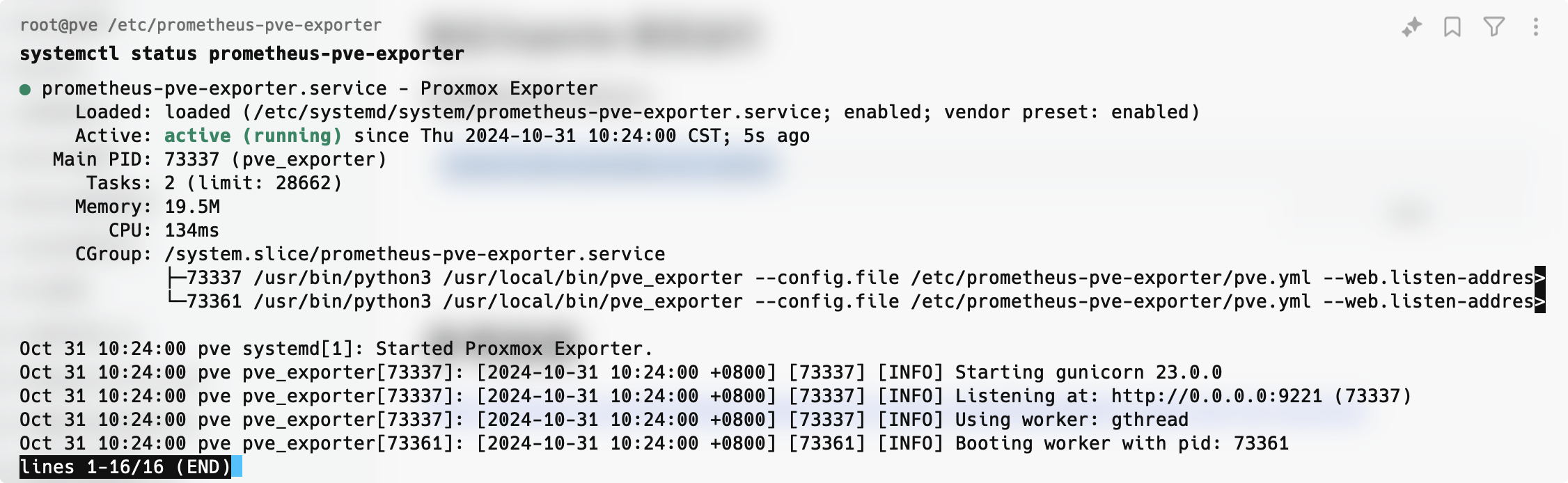
通过systemctl status xxx来检查某个服务是否正常启动。
systemctl status prometheus-pve-exporter
如果正常运行,你能看到如下所示的输出,浏览器访问:http://<PVE_SERVER_IP>:9221/pve 就能看到数据了
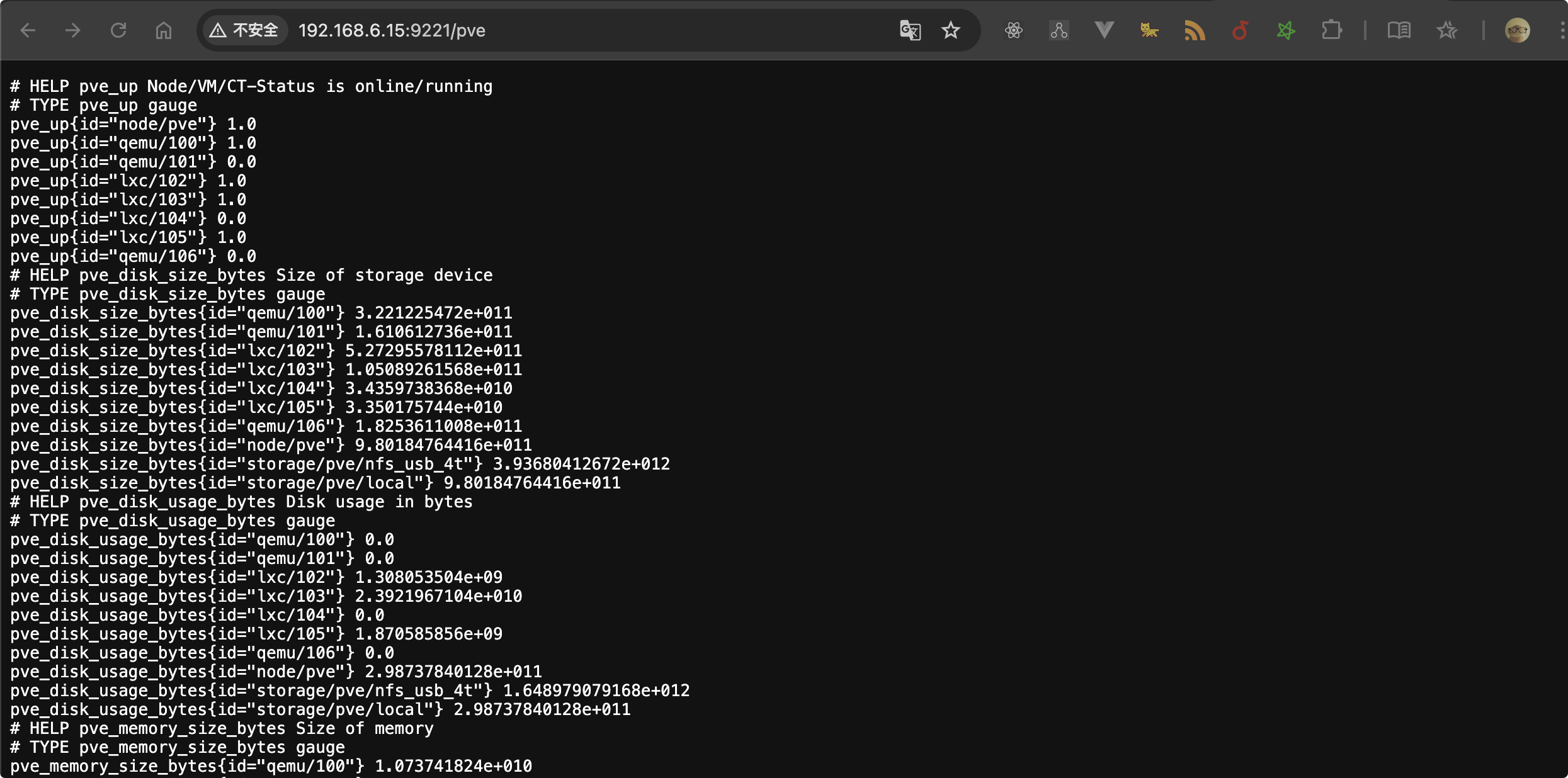
配置 Alertmanager
该工具用于发送邮件,执行以下命令来安装:
wget https://github.com/prometheus/alertmanager/releases/download/v0.25.0/alertmanager-0.25.0.linux-amd64.tar.gz
tar -xvzf alertmanager-0.25.0.linux-amd64.tar.gz
sudo mv alertmanager-0.25.0.linux-amd64/alertmanager /usr/local/bin/
创建 Alertmanager 配置文件:
nvim /etc/alertmanager/alertmanager.yml
添加下述内容:
smtp_smarthost为邮箱的服务器地址smtp_from为发件人地址smtp_auth_username为发件人的登陆用户名smtp_auth_password为发件人的登陆授权码smtp_require_tlsqq 邮箱用 465 端口的话,需要将其设置为 false
global:
smtp_smarthost: 'smtp.qq.com:465'
smtp_from: '[email protected]'
smtp_auth_username: '[email protected]'
smtp_auth_password: 'xxxxx'
smtp_require_tls: false
# smtp_tls: true
route:
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: '[email protected]'
send_resolved: true
创建 systemd 服务文件
nvim /etc/systemd/system/alertmanager.service
添加下述内容:
[Unit]
Description=Alertmanager Service
After=network.target
[Service]
ExecStart=/usr/local/bin/alertmanager --config.file=/etc/alertmanager/alertmanager.yml
Restart=always
[Install]
WantedBy=multi-user.target
重载配置,启动服务,添加开机自启
systemctl daemon-reload
systemctl enable alertmanager
systemctl start alertmanager
最后,我们验证下 Alertmanager 是否正常运行,访问 http://<你的 PVE 主机 IP>:9093,你将看到 Alertmanager 的 Web 界面。
创建告警规则
选择你熟悉的编辑器来创建,我这里使用的是nvim
nvim /etc/prometheus/alert.rules.yml
你可以按照你的需求去写相应的告警规则,此处以我的需求为例,我要监控 ID 为 100 的虚拟机,如果内存占用在 80%以上且持续 2 分钟,就触发。
- alert 邮件发送时的标题
- expr 为要执行的PromQL 表达式
- for 为持续时间
- annotations 为邮件的具体内容
groups:
- name: node_alerts
rules:
- alert: "web 服务器内存使用率过高"
expr: 100 * (pve_memory_usage_bytes{id="qemu/100"} / pve_memory_size_bytes{id="qemu/100"}) > 80
for: 2m
labels:
severity: critical
annotations:
summary: "alpine-linux 虚拟机已使用 ({{ $value }}%的内存)"
description: "虚拟机 ID 为 100 ,内存使用率已超过 80%,请检查进程情况。"
注意⚠️:这里创建的告警规则会在 Prometheus 的配置文件里被引用。
配置 Prometheus
该工具用于采集prometheus-pve-exporter提供的数据并进行监控。进入 pve 的后台,执行以下命令来安装 :
apt update && apt install prometheus -y
随后,编辑 Prometheus 的配置文件。
nvim /etc/prometheus/prometheus.yml
添加下述内容,Pve Exporter 作为数据来源:
global:
scrape_interval: 15s # 每 15 秒采集一次数据
evaluation_interval: 15s # 每 15 秒评估一次规则
external_labels:
monitor: 'example'
# Alertmanager 配置
alerting:
alertmanagers:
- static_configs:
- targets: ['localhost:9093']
# 加载告警规则文件
rule_files:
- "/etc/prometheus/alert.rules.yml"
# 采集配置
scrape_configs:
# Prometheus 自身的监控
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
# 监控 PVE 主机
- job_name: 'node'
static_configs:
- targets: ['localhost:9221']
metrics_path: /pve
params:
module: [default]
cluster: ['1']
node: ['1']
重启 Prometheus 服务。
systemctl daemon-reload
systemctl reload prometheus
systemctl restart prometheus
最后,在浏览器访问:http://<PVE_SERVER_IP>:9090 就能看到它的 web 面板了。
配置 Grafana
进入 pve 后台,执行下述命令。
apt install -y software-properties-common
add-apt-repository "deb https://packages.grafana.com/oss/deb stable main"
wget -q -O - https://packages.grafana.com/gpg.key | apt-key add -
apt update && apt install grafana -y
安装成功后,执行下述命令来启动服务并添加到开机自启项里。
systemctl start grafana-server
systemctl enable grafana-server
通过浏览器访问http://<PVE 主机 IP>:3000,默认账号为 admin,密码为 admin。
添加 Prometheus 数据源
在 Grafana 的 Web 界面中,进入 Connections -> Data Sources,添加 Prometheus 数据源,URL 填写为 http://localhost:9090。
测试和验证告警服务
通过stress工具可以模拟高内存占用,如果未安装的话,需执行下述命令来安装。
apt install stress
运行以下命令人为增加系统内存占用
- 增加 5G 内存占用,持续 130s
stress --vm 1 --vm-bytes 5G --timeout 130s
不出意外的话,你将会收到Alertmanager发出的邮件,在 Prometheus 的 Web 界面中,Alerts 标签下也会收到告警消息。
服务地址
本章节我们来归纳下这 4 个服务的的访问地址:
prometheus-pve-exporterhttp://<PVE_SERVER_IP>:9221/pveAlertmanagerhttp://<你的 PVE 主机 IP>:9093Prometheushttp://<你的 PVE 主机 IP>:9090Grafanahttp://<PVE 主机 IP>:3000
写在最后
至此,文章就分享完毕了。
我是神奇的程序员,一位前端开发工程师。
如果你对我感兴趣,请移步我的个人网站,进一步了解。
- 文中如有错误,欢迎在评论区指正,如果这篇文章帮到了你,欢迎点赞和关注😊
- 本文首发于神奇的程序员公众号,未经许可禁止转载💌
14 条回复 • 2024-11-01 13:16:37 +08:00
 |
1
llussy 54 天前
感谢分享
|
 |
2
Biggoldfish 54 天前 虽然是转载来的文章,但还是忍不住说几句
1. 你把一整套 monitoring stack 都搭在被 monitor 的 PVE 机器上,要是 PVE host machine 挂了呢? 2. 相比直接在 PVE host machine 上 apt install 装一堆服务,用 LXC container 是否是更好的方案? 3. 好歹套一层 Nginx 或其他的 reverse proxy ,直接 http 协议用 ip + port 访问也太粗糙了点 |
 |
3
zhengfan2016 54 天前 via Android
@Biggoldfish 1.2 完全支持,甚至我觉得用 docker-compose 管理是更好的选择,3 看起来是局域网内用的,如果是放在公网确实该吐槽。
|
|
4
Biggoldfish 54 天前 via Android
@zhengfan2016 个人确实也更喜欢用 docker 不过这方面各有所爱了
3 的话如果这是个 toy project/homelab ,那么大概率不需要这一整套复杂的 monitoring & alerting ,等什么时候发现挂了再修就是。如果是 prod use case ,那内网也应该 zero trust 而不是直接 HTTP 裸连 ip🤣 |
 |
5
BaymaxK OP @Biggoldfish 嗯嗯 这些服务只有 prometheus-pve-exporter 一定是要装在主机上的,其他的可以选择开一个 lxc 容器来跑。我这套服务是跑在内网的,在外面需要用的时候,通过 vpn 连回去的。
|
 |
6
EvineDeng 54 天前
其实 PVE 自带 metricservers 功能,本身就支持提交到 Graphite 或 InfluxDB 服务器,而 InfluxDB 搭配 Grafana 就已经可以实现图表可视化及自动告警了。
|
|
8
EvineDeng 54 天前
PVE 自带 metricservers 功能完全不需要在 PVE 主机中额外搭建任何服务了。
|
 |
9
cJ8SxGOWRH0LSelC 54 天前
还不如部署一个哪吒探针, 你这一套看的我头皮发麻
|
 |
10
defunct9 54 天前
都手搓这么多东西了,还用个毛线的 PVE ,太 Low 了,手搓 KVM 才是王道。
|
|
11
BaymaxK OP @StinkyTofus 好家伙,看了下这个产品,确实方便啊。我在折腾前还是调研做的少了😂
|
 |
12
xinmans 54 天前
pve 的 vm 的内存泄漏问题确实很严重,你一般是重启 VM 还是 PVE 解决?
|
 |
14
tianshiyeben 54 天前
https://www.wgstart.com/ 这个比较轻量 部署一套就满足你的场景了
|