
这是一个创建于 1438 天前的主题,其中的信息可能已经有所发展或是发生改变。
本文为 #nLive vol.001 |美团图数据库平台建设及业务实践# 主题演讲的文字稿,可前往 B 站 观看本次视频

大家好,我是来自美团的赵登昌,今天我给大家分享下美团图数据库平台的建设以及业务实践。

这是本次报告的提纲,主要包括以下六方面内容。
背景介绍

首先介绍下美团在图数据方面的业务需求。

美团内部有比较多的图数据存储以及多跳查询需求,总体来说有以下 4 个方面:
第一个方面是知识图谱方向,美团内部有美食图谱、商品图谱、旅游图谱在内的近 10 个领域知识图谱,数据量级大概在千亿级别。在迭代、挖掘数据的过程中,需要一种组件对这些图谱数据进行统一管理。
第二个方面是安全风控。业务部门有内容风控的需求,希望在商户、用户、评论中通过多跳查询来识别虚假评价;在支付时进行金融风控验证,实时多跳查询风险点。
第三个方面是链路分析,比如说:数据血缘管理,公司数据平台上有很多 ETL Job,Job 和 Job 之间存在强弱依赖关系,这些强弱依赖关系形成了一张图,在进行 ETL Job 的优化或者故障处理时,需要对这个图进行分析。类似的需求还有代码分析、服务治理等。
第四个方面是组织架构管理,包括:公司组织架构的管理,实线汇报链、虚线汇报链、虚拟组织的管理,以及商家连锁门店的管理。比如,需要管理一个商家在不同区域都有哪些门店,能够进行多层关系查找或者逆向关系搜索。
总体来说,我们需要一种组件来管理千亿级别的图数据,解决图数据存储以及多跳查询问题。
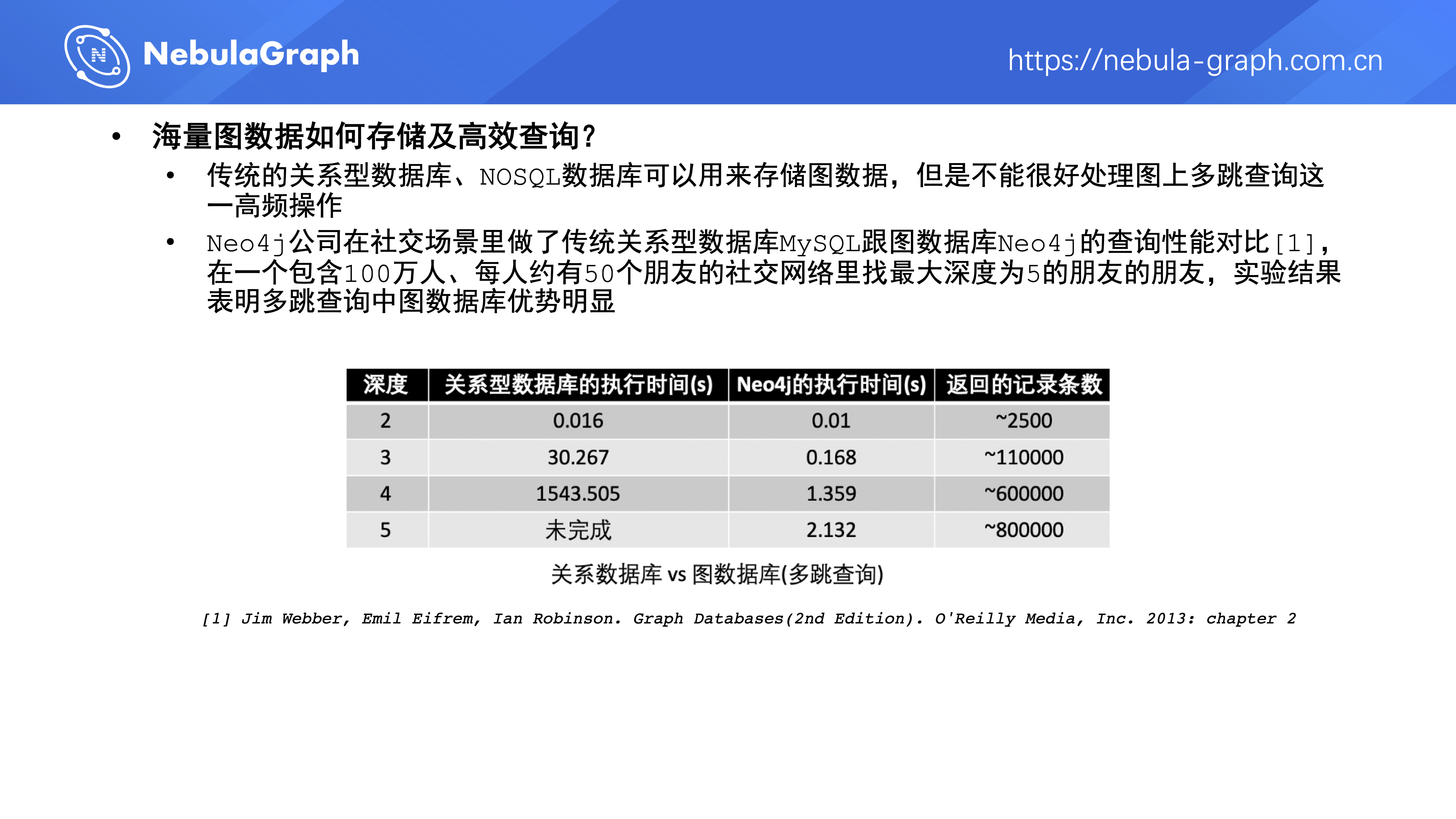
传统的关系型数据库、NoSQL 数据库可以用来存储图数据,但是不能很好处理图上多跳查询这一高频操作。Neo4j 公司在社交场景做了 MySQL 和 Neo4j 的多跳查询性能对比,具体测试场景是,在一个 100 万人、每个人大概有 50 个朋友的社交网络里找最大深度为 5 的朋友的朋友。从测试结果看,查询深度增大到 5 时,MySQL 已经查不出结果了,但 Neo4j 依然能在秒级返回数据。实验结果表明多跳查询中图数据库优势明显。
图数据库选型

下面介绍我们的图数据库选型工作。

我们主要有以下 5 个图数据库选型要求
- A. 项目开源,暂时不考虑需要付费的图数据库;
- B. 分布式的架构设计,具备良好的可扩展性;
- C. 毫秒级的多跳查询延迟;
- D. 支持千亿量级点边存储;
- E. 具备批量从数仓导入数据的能力。
我们分析了 DB-Engine 上排名 Top30 的图数据库,剔除不开源的项目后,把剩下的图数据库分成三类。
- 第一类包括 Neo4j 、ArangoDB 、Virtuoso 、TigerGraph 、RedisGraph 。此类图数据库只有单机版本开源可用,性能比较优秀,但是不能应对分布式场景中数据的规模增长,即不满足选型要求 B 、D ;
- 第二类包括 JanusGraph 、HugeGraph 。此类图数据库在现有存储系统之上新增了通用的图语义解释层,图语义层提供了图遍历的能力,但是受到存储层或者架构限制,不支持完整的计算下推,多跳遍历的性能较差,很难满足 OLTP 场景下对低延时的要求,即不满足选型要求 C ;
- 第三类包括 Dgraph 、Nebula Graph 。此类图数据库根据图数据的特点对数据存储模型、点边分布、执行引擎进行了全新设计,对图的多跳遍历进行了深度优化,基本满足我们对图数据库的选型要求

之后我们在一个公开社交数据集上(大约 200 亿点边)对 Nebula Graph 、Dgraph 、HugeGraph 进行了深度性能测评。主要从三个方面进行评测:
- 批量数据的导入
- 实时写入性能测试
- 数据多跳查询性能测试
测试详情见 Nebula 论坛:主流开源分布式图数据库 Benchmark 🔗
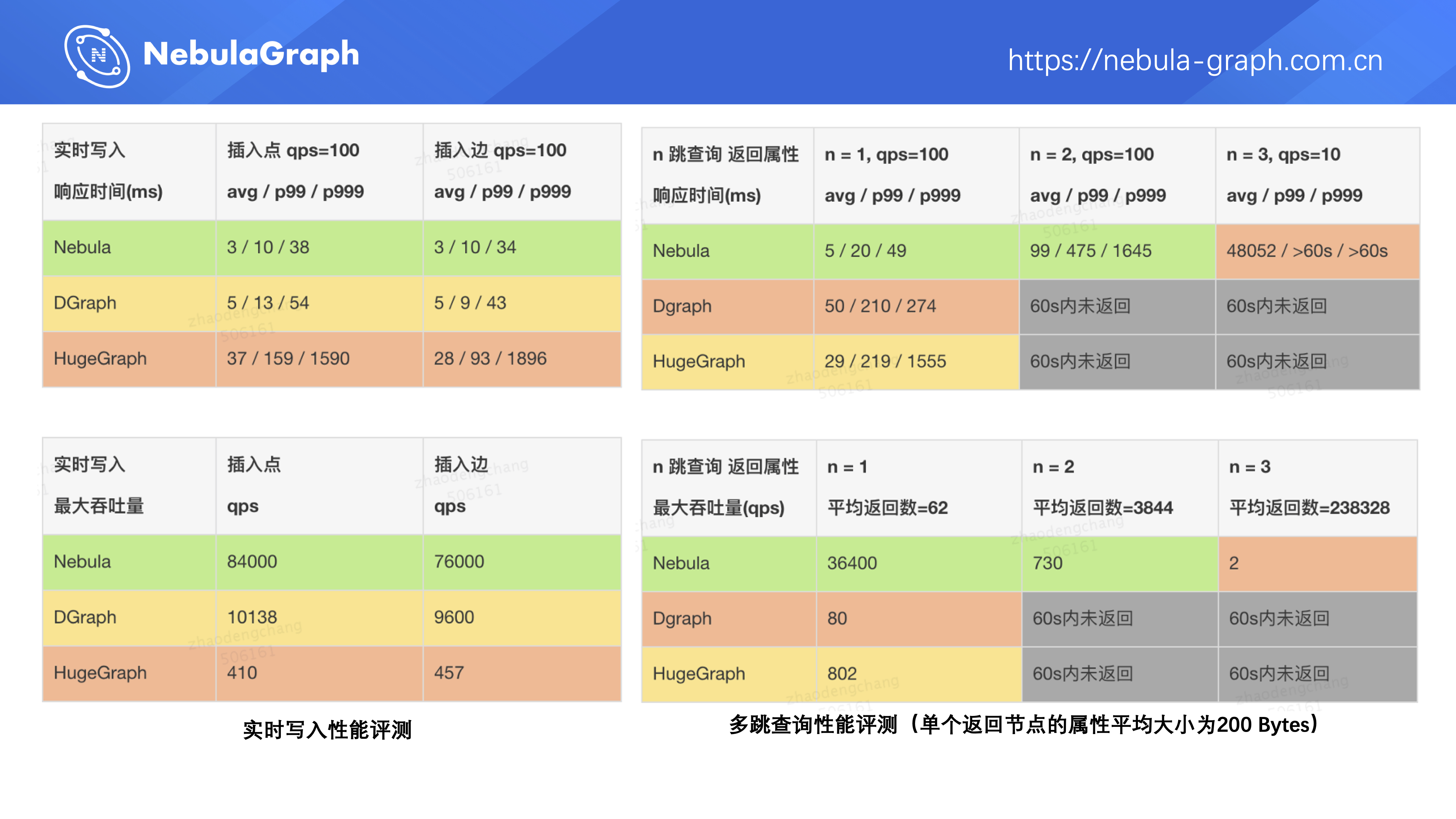
从测试结果看 Nebula Graph 在数据导入、实时写入及多跳查询方面性能均优于竞品。此外,Nebula Graph 社区活跃,问题的响应速度快,所以团队最终选择了基于 Nebula Graph 来搭建图数据库平台。
图数据库平台建设

下面介绍美团图数据库平台的建设,整个图数据库平台包括 4 层。
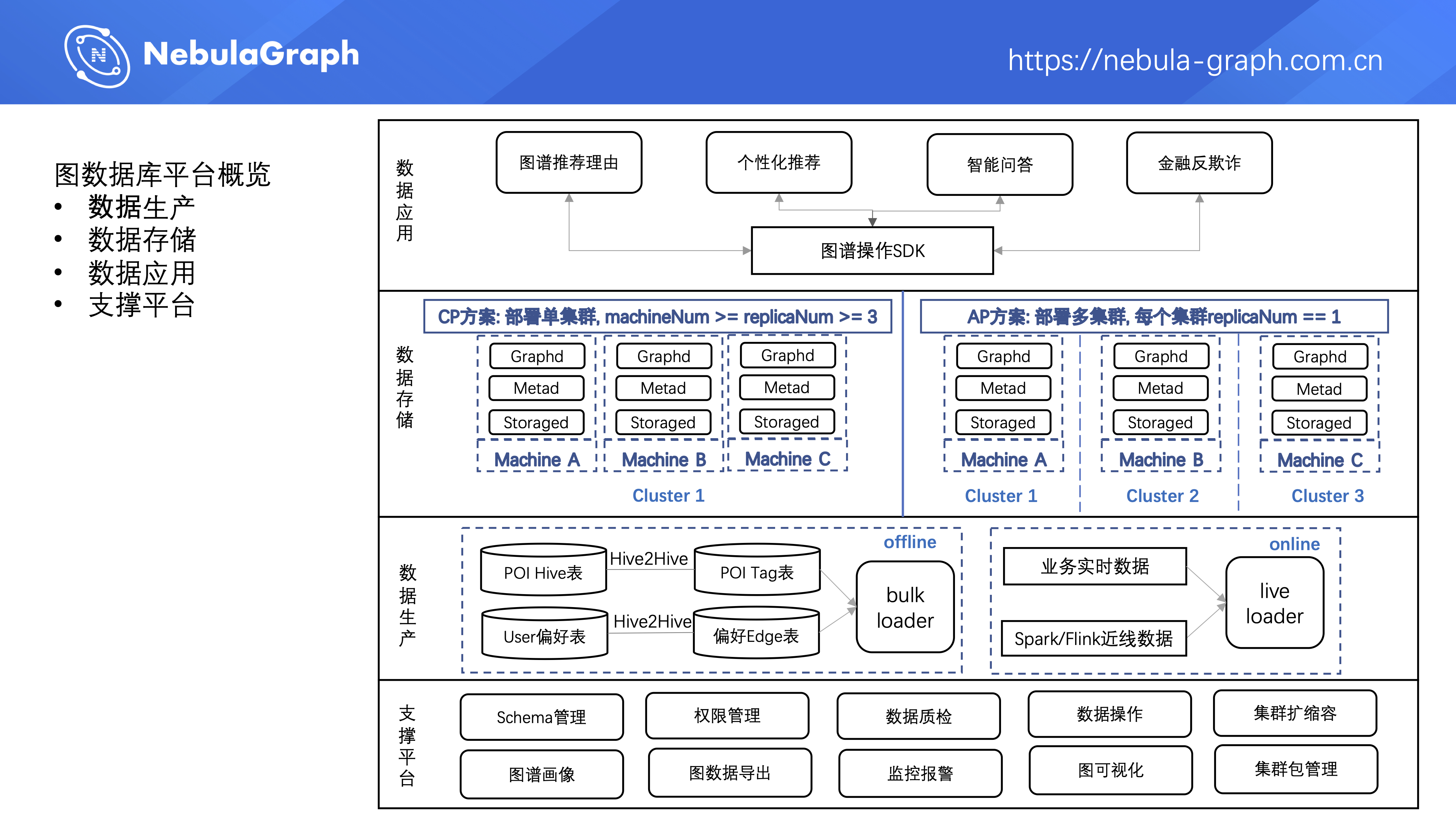
第一层是数据生产层,平台的图数据主要有两种来源,第一种是业务方把数仓中数据通过 ETL Job 转成点和边的 Hive 表,然后离线导入到图数据库中;第二种是业务线上实时产生的数据、或者通过 Spark 、Flink 等流式处理产生的近线数据,实时地通过 Nebula Graph 提供的在线批量接口灌到图数据库中。
第二层是数据存储层,平台支持两种图数据库集群的部署方式。
- 第一种是 CP 方案,即 Consistency & Partition tolerance,这是 Nebula Graph 原生支持的集群部署方式。单集群部署,集群中机器数量大于等于副本的数量,副本数量大于等于 3 。只要集群中有大于副本数一半的机器存活,整个集群就可以对外正常提供服务。CP 方案保证了数据读写的强一致性,但这种部署方式下集群可用性不高。
- 第二种部署方式是 AP 方案,即 Availability & Partition tolerance,在一个应用中部署多个图数据库集群,每个集群数据副本数为 1,多集群之间进行互备。这种部署方式的好处在于整个应用对外的可用性高,但数据读写的一致性要差点。
第三层是数据应用层,业务方可以在业务服务中引入平台提供的图谱 SDK,实时地对图数据进行增删改查。
第四层是支撑平台,提供了 Schema 管理、权限管理、数据质检、数据增删改查、集群扩缩容、图谱画像、图数据导出、监控报警、图可视化、集群包管理等功能。
经过这四层架构设计,目前图数据库平台基本具备了对图数据的一站式自助管理功能。如果某个业务方要使用这种图数据库能力,那么业务方可以在这个平台上自助地创建图数据库集群、创建图的 Schema 、导入图数据、配置导入数据的执行计划、引入平台提供的 SDK 对数据进行操作;平台侧主要负责各业务方图数据库集群的稳定性。目前有三、四十个业务在平台上真正落地,基本能满足各个业务方需求。
再介绍下图数据库平台中几个核心模块的设计。
高可用模块设计
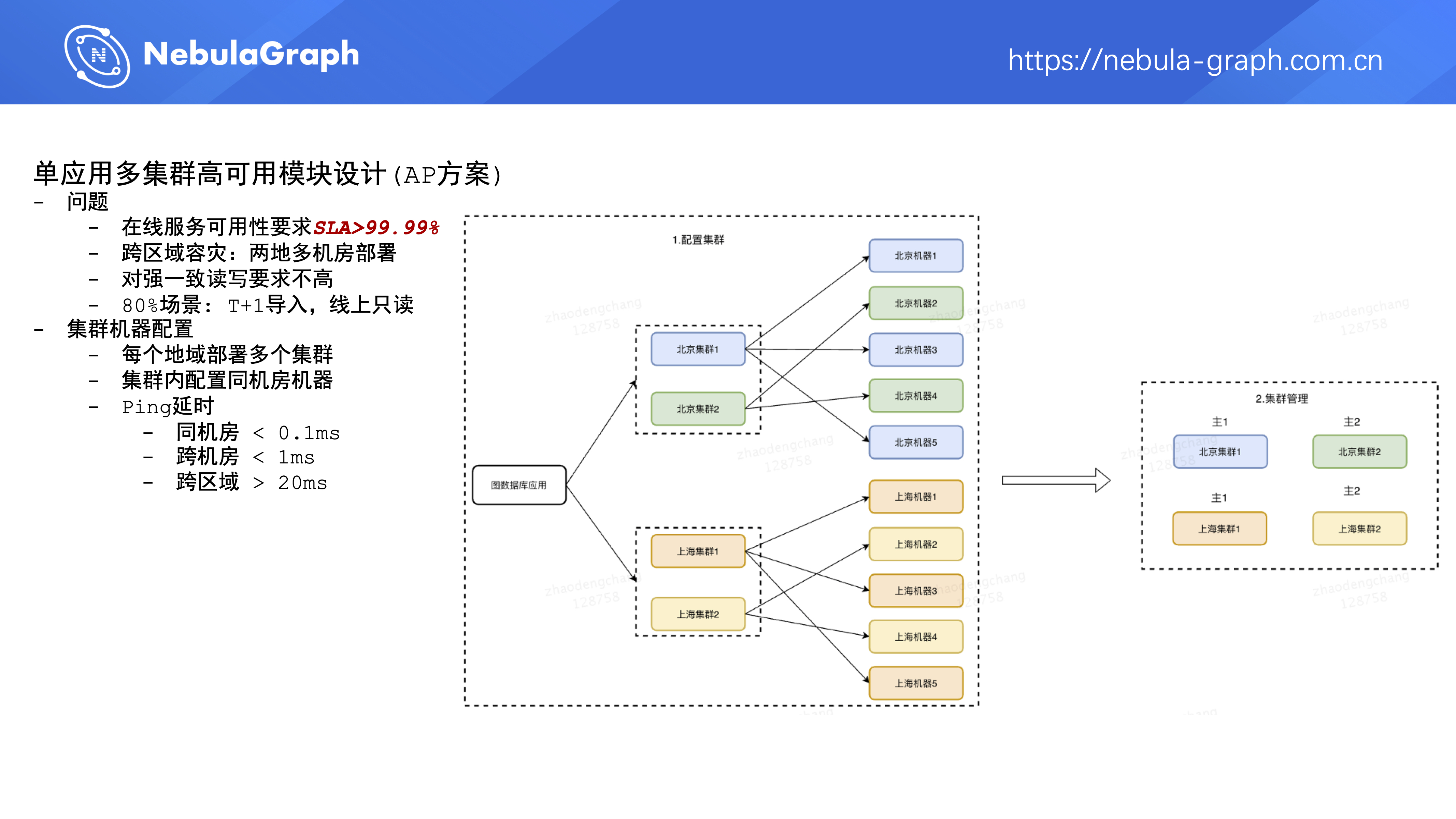
首先是单应用多集群高可用模块的设计( AP 方案)。为什么有 AP 方案的设计呢?因为接入这个图数据库平台的业务方比较在意的指标是集群可用性。在线服务对集群的可用性要求非常高,最基础的要求是集群可用性能达到 4 个 9,即一年里集群的不可用时间要小于一个小时,对于在线服务来说,服务或者集群的可用性是整个业务的生命线,如果这点保证不了,即使集群提供的能力再多再丰富,那么业务方也不会考虑使用,可用性是业务选型的基础。
另外公司要求中间件要有跨区域容灾能力,即要具备在多个地域部署多集群的能力。我们分析了平台接入方的业务需求,大约 80% 的场景是 T+1 全量导入数据、线上只读;在这种场景下对图数据的读写强一致性要求并不高,因此我们设计了单应用多集群这种部署方案。
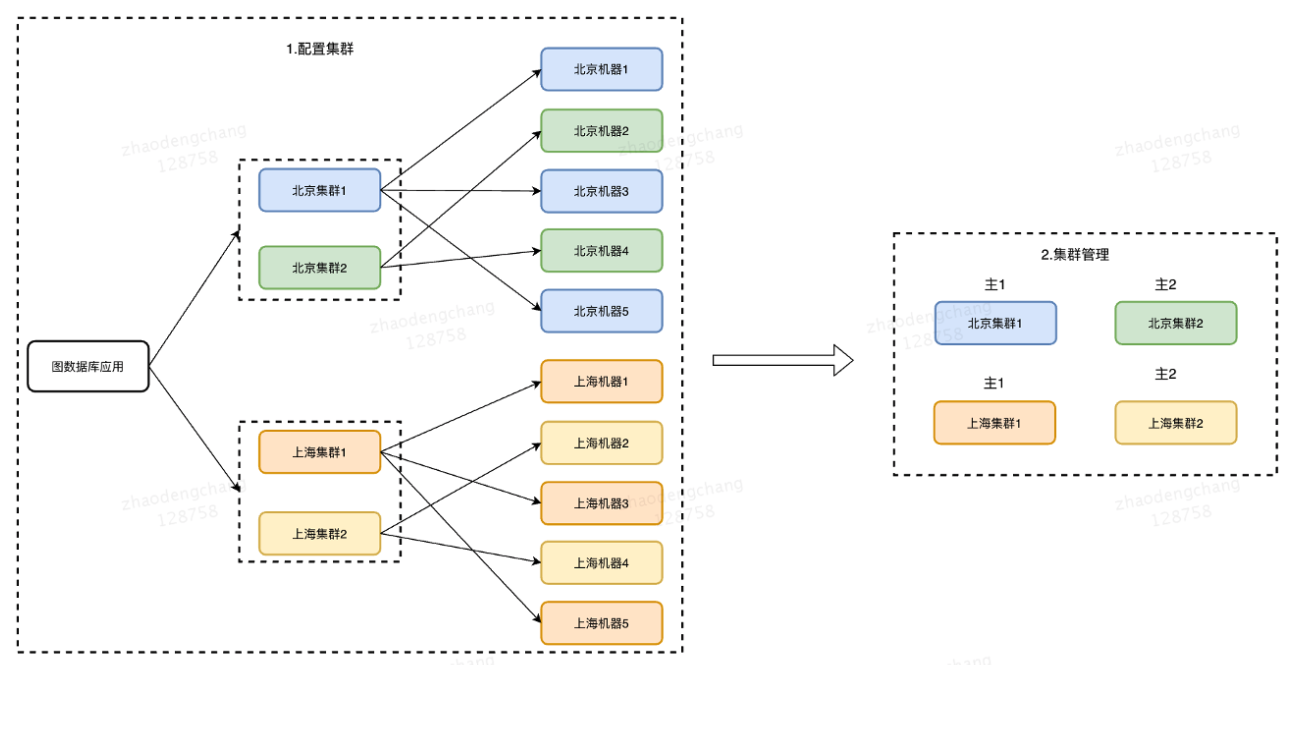
部署方式可以参考上图,一个业务方在图数据库平台上创建了 1 个应用并部署了 4 个集群,其中北京 2 个、上海 2 个,平时这 4 个集群同时对外提供服务。假如现在北京集群 1 挂了,那么北京集群 2 可以提供服务。如果说真那么不巧,北京集群都挂了,或者对外的网络不可用,那么上海的集群可以提供服务,这种部署方式下,平台会尽可能地通过一些方式来保证整个应用的可用性。然后每个集群内部尽量部署同机房的机器,因为图数据集群内部 RPC 是非常多的,如果有跨机房或者跨区域的频繁调用,整个集群对外的性能会比较低。
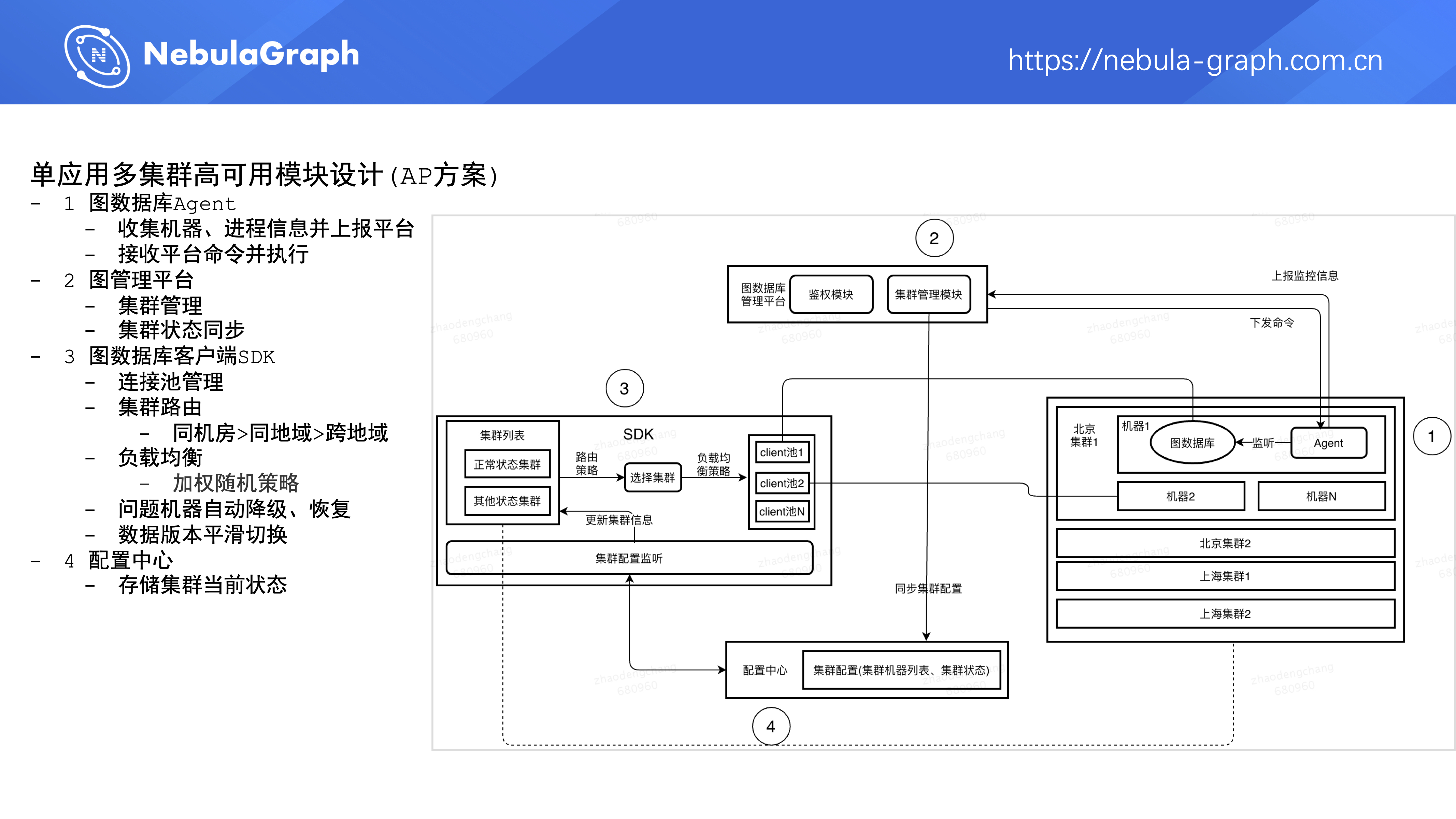
这个 AP 模块的设计主要包含下面 4 个部分:
- 第一部分是右侧的图数据库 Agent,它是部署在图数据库集群的一个进程,用来收集机器和 Nebula Graph 三个核心模块的信息,并上报到图数据库平台。Agent 能够接收图数据库平台的命令并对图数据库进行操作。
- 第二部分是图管理平台,它主要是对集群进行管理,并同步图数据库集群的状态到配置中心。
- 第三部分是图数据库 SDK,它主要做的事情是管理连接到图数据库集群的连接。如果业务方发送了某个查询请求,SDK 会进行集群的路由和负载均衡,选择出一条高质量的连接来发送请求。此外,SDK 还会处理图数据库集群中问题机器的自动降级以及恢复,并且要支持平滑切换集群的数据版本。
- 第四部分是配置中心,类似 ZooKeeper,存储集群的当前状态。
每小时百亿级数据导入模块设计
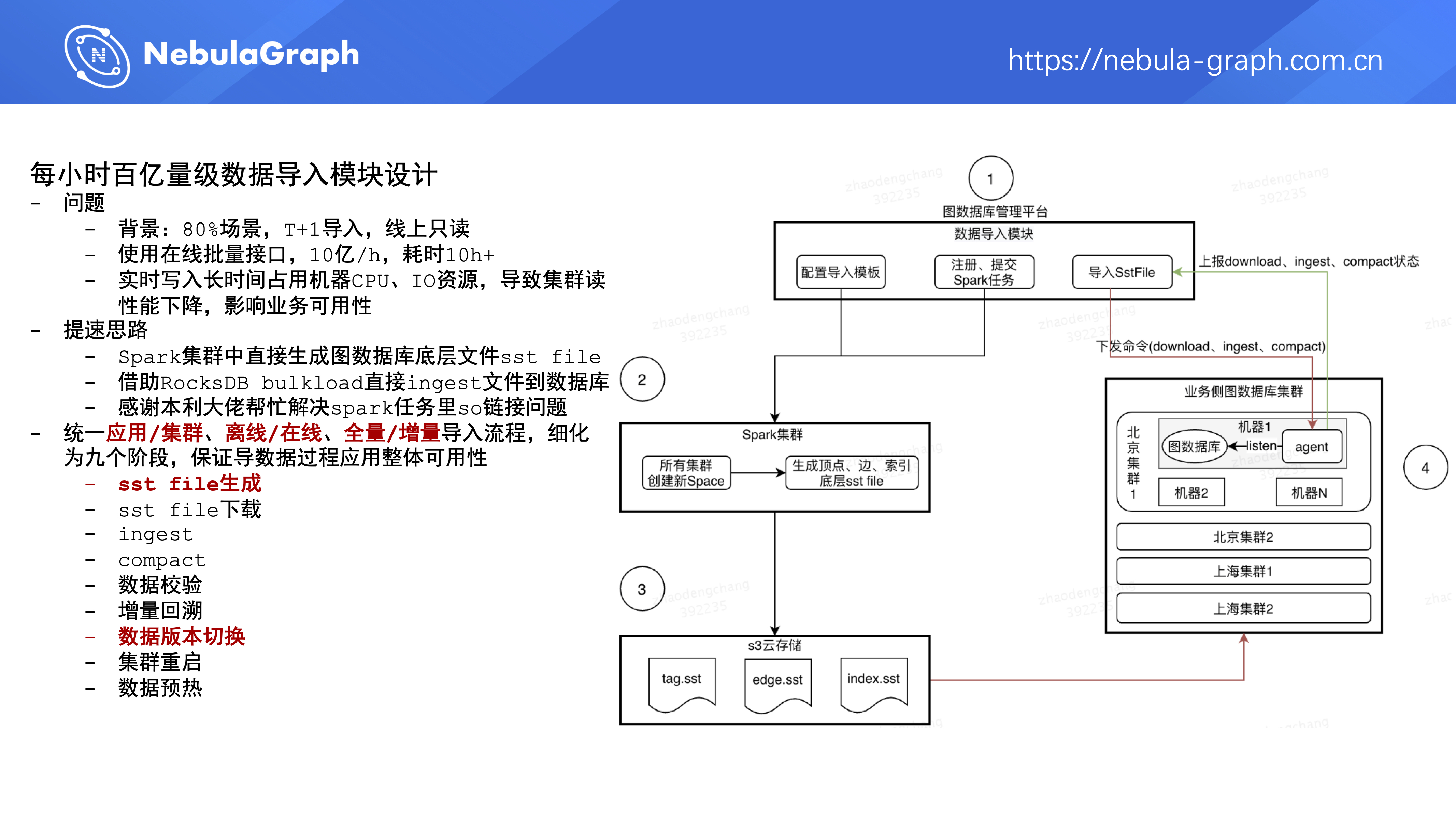
第二个模块是每小时百亿量级数据导入模块,上面说了业务场景里 80% 是 T+1 全量导入数据,然后线上只读。平台在 19 年底 / 20 年初全量导入数据的方式是调用 Nebula Graph 对外提供的批量数据导入接口,这种方式的数据写入速率大概是每小时 10 亿级别,导入百亿数据大概要耗费 10 个小时,这个时间有点久。此外,在以几十万每秒的速度导数据的过程中,会长期占用机器的 CPU 、IO 资源,一方面会对机器造成损耗,另一方面数据导入过程中集群对外提供的读性能会变弱。
为了解决上面两个问题,平台进行了如下优化:在 Spark 集群中直接生成图数据库底层文件 sst file,再借助 RocksDB 的 bulkload 功能直接 ingest 文件到图数据库。这部分提速优化工作在 19 年底的时候就开始了,但是中间遇到 core dump 问题没有上线。在 20 年六、七月份的时候,微信的本利大佬向社区提交了这方面的 pr,和他在线沟通之后解决了我们的问题,在这里感谢一下本利大佬 💐 。
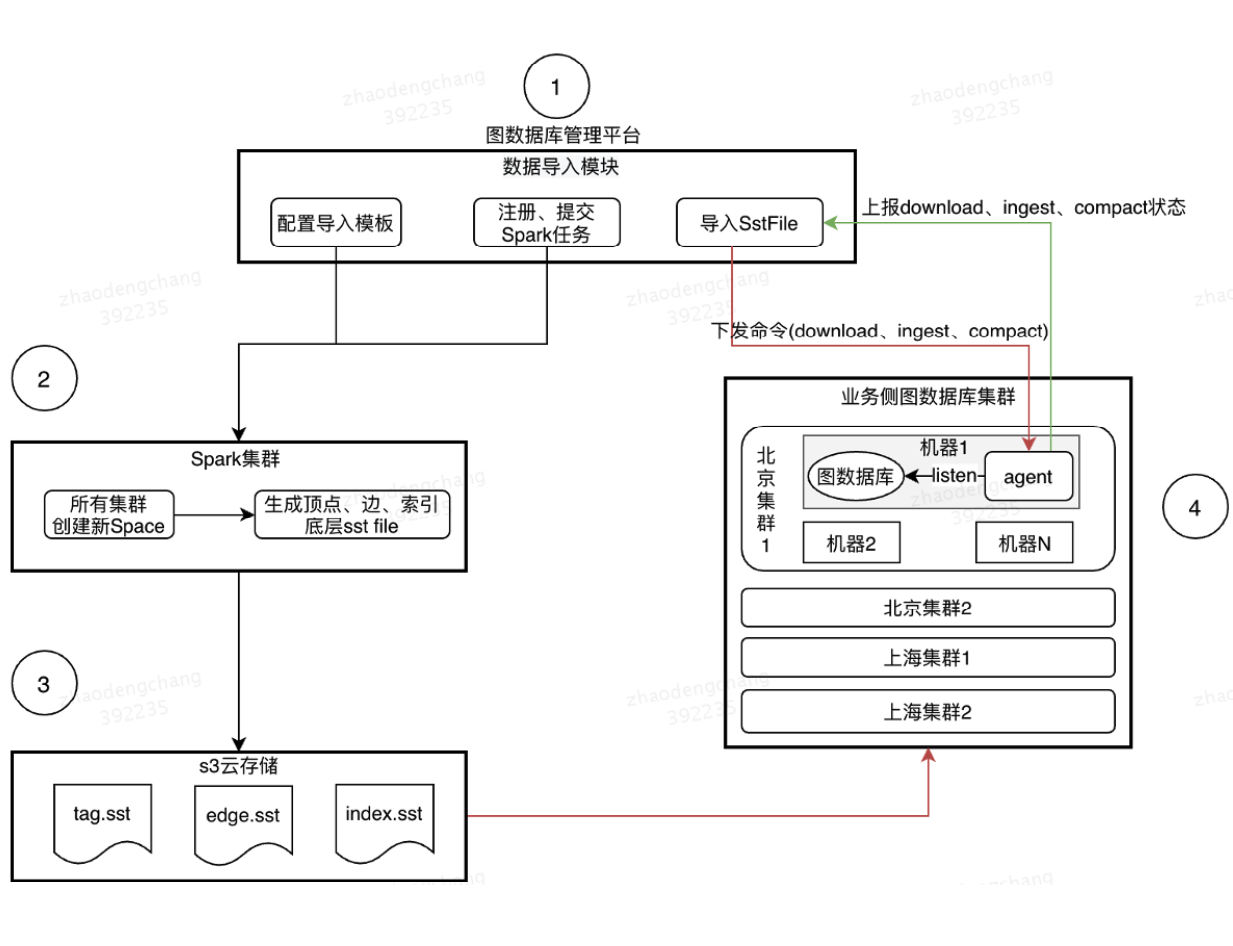
图数据库平台数据导入的核心流程可以看右边这张图,当用户在平台上提交了导数据操作后,图数据库平台会向公司的 Spark 集群提交一个 Spark 任务,在 Spark 任务中会生成图数据库里相关的点、边以及点索引、边索引相关的 sst 文件,并上传到公司的 S3 云存储上。文件生成后,图数据库平台会通知应用里的多个集群去下载这些存储文件,之后完成 ingest 跟 compact 操作,最后完成数据版本的切换。
平台方为兼顾各个业务方的不同需求,统一了应用导入、集群导入、离线导入、在线导入以及全量导入、增量导入这些场景,然后细分成下面九个阶段,从流程上保证在导数据过程中应用整体的可用性。
- sst file 生成
- sst file 下载
- ingest
- compact
- 数据校验
- 增量回溯
- 数据版本切换
- 集群重启
- 数据预热
实时写入多集群数据同步模块设计
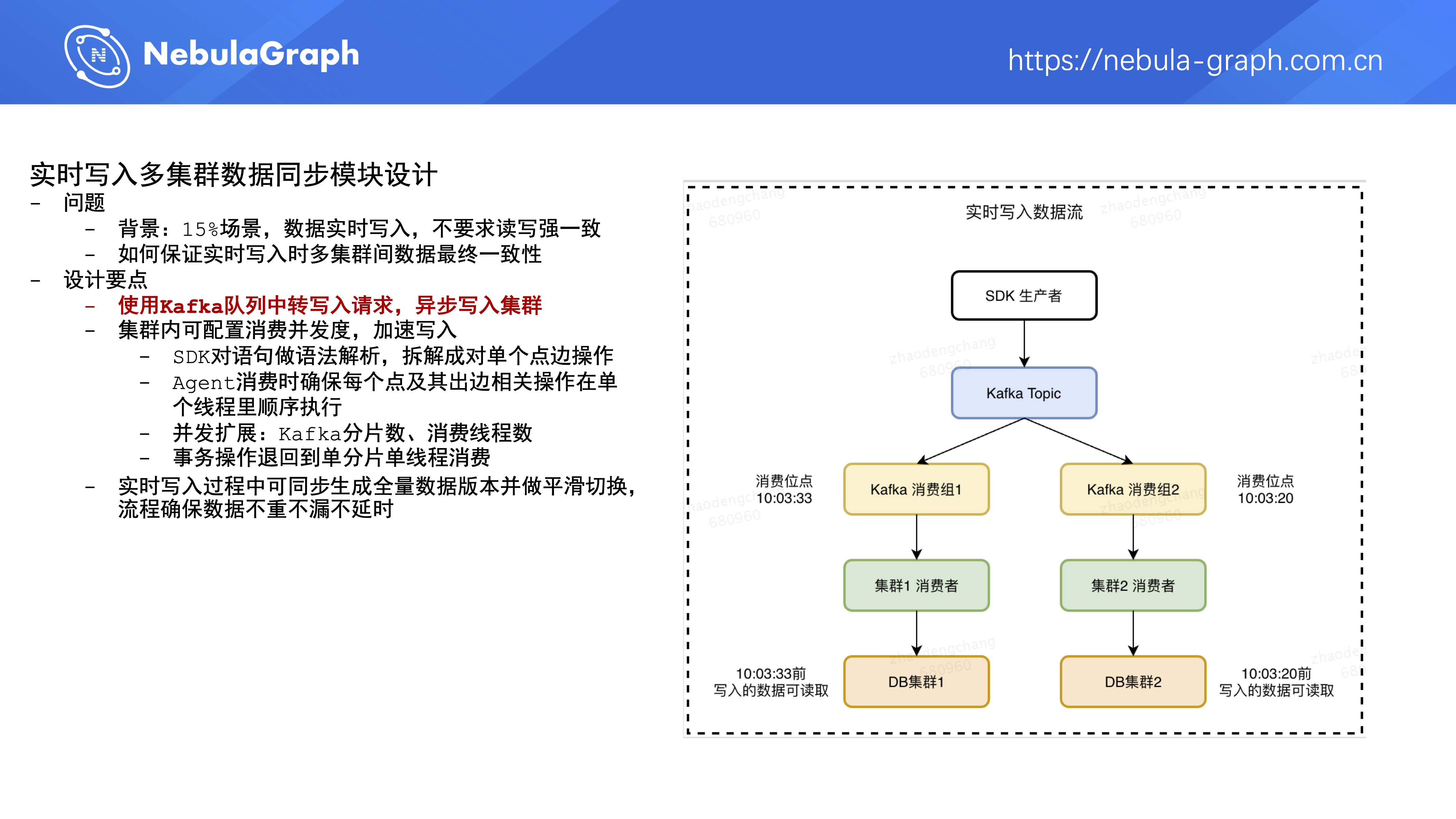
第三个模块是实时写入多集群数据同步,平台有 15% 的需求场景是在实时读取数据时,还要把新产生的业务数据实时写入集群,并且对数据的读写强一致性要求不高,就是说业务方写到图数据库里的数据,不需要立马能读到。
针对上述场景,业务方在使用单应用多集群这种部署方案时,多集群里的数据需要保证最终一致性。平台做了以下设计,第一部分是引入 Kafka 组件,业务方在服务中通过 SDK 对图数据库进行写操作时,SDK 并不直接写图数据库,而是把写操作写到 Kafka 队列里,之后由该应用下的多个集群异步消费这个 Kafka 队列。
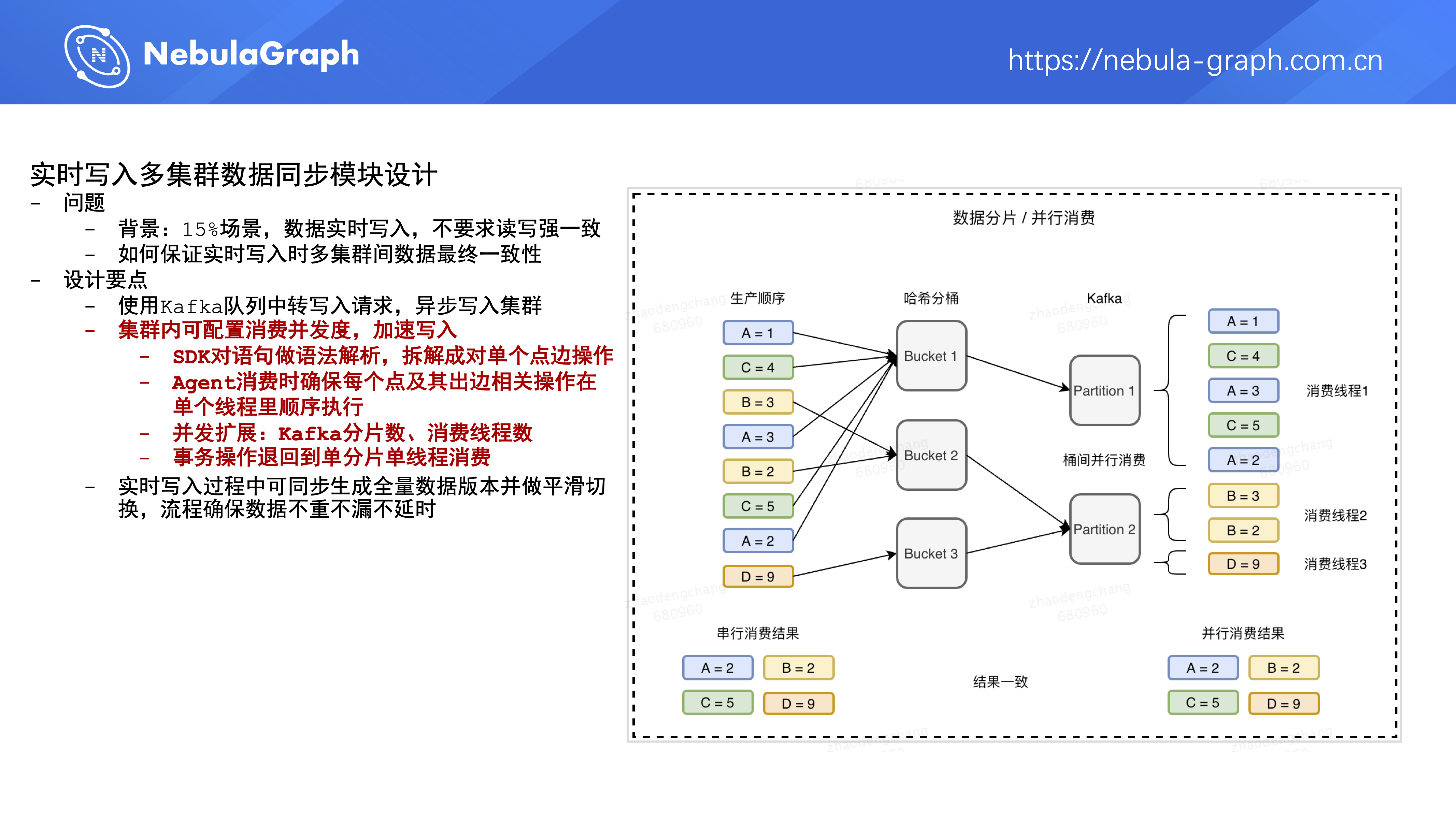
第二部分是集群在应用级别可配置消费并发度,来控制数据写入集群的速度。具体流程是
- SDK 对用户写操作语句做语法解析,将其中点边的批量操作拆解成对单个点边操作,即对写语句做一次改写
- Agent 消费 Kafka 时确保每个点及其出边相关操作在单个线程里顺序执行,保证这点就能保证各个集群执行完写操作后最终的结果是一致的。
- 并发扩展:通过改变 Kafka 分片数、Agent 中消费 Kafka 线程数来变更和调整 Kafka 中操作的消费速度。
- 如果未来 Nebula Graph 支持事务的话,上面的配置需要调整成单分片单线程消费,平台需要对设计方案再做优化调整。
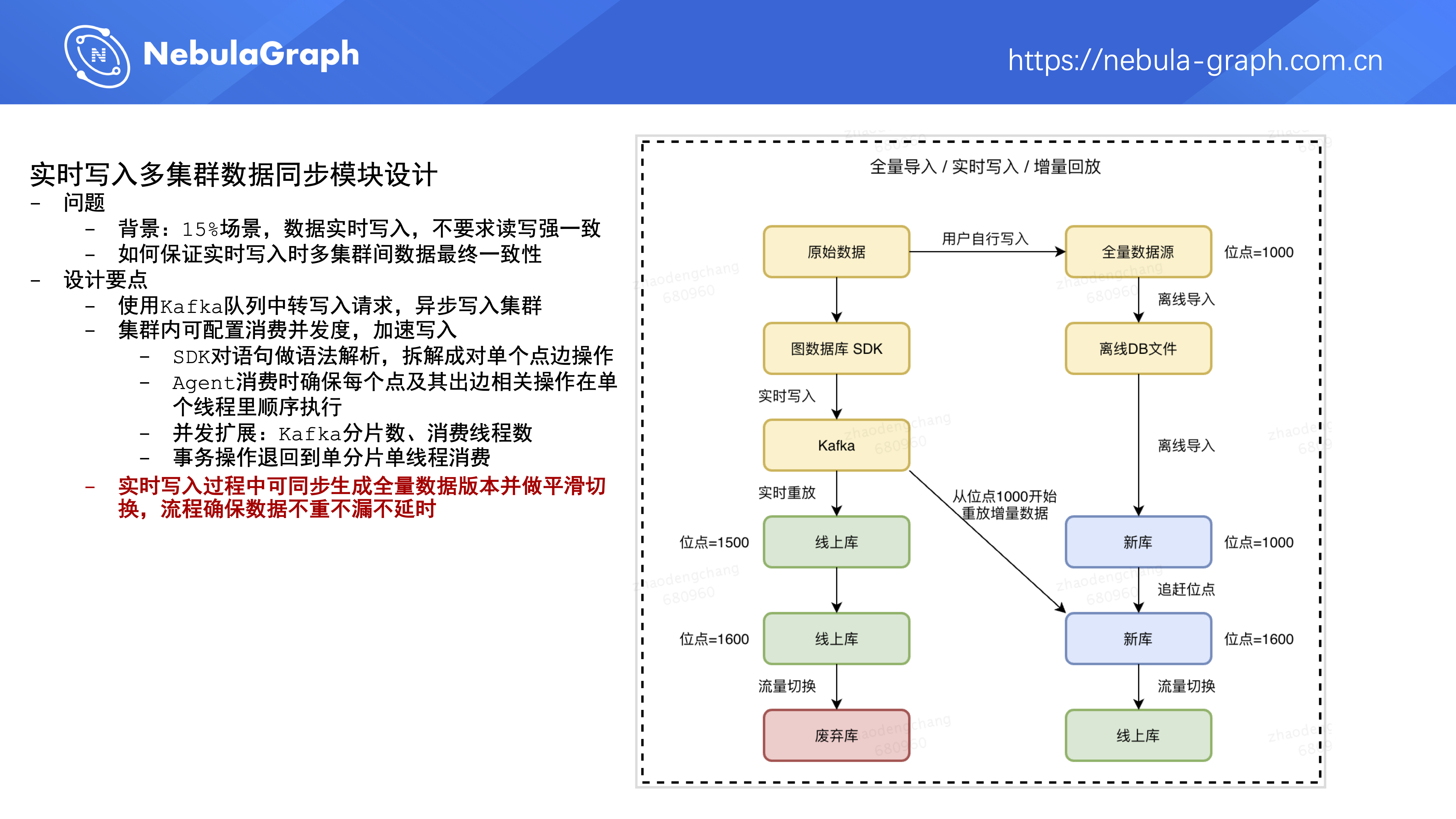
第三部分是在实时写入数据过程中,图数据库平台可以同步生成一个全量数据版本,并做平滑切换,通过右图里的流程来确保数据的不重不漏不延迟。
图可视化模块设计
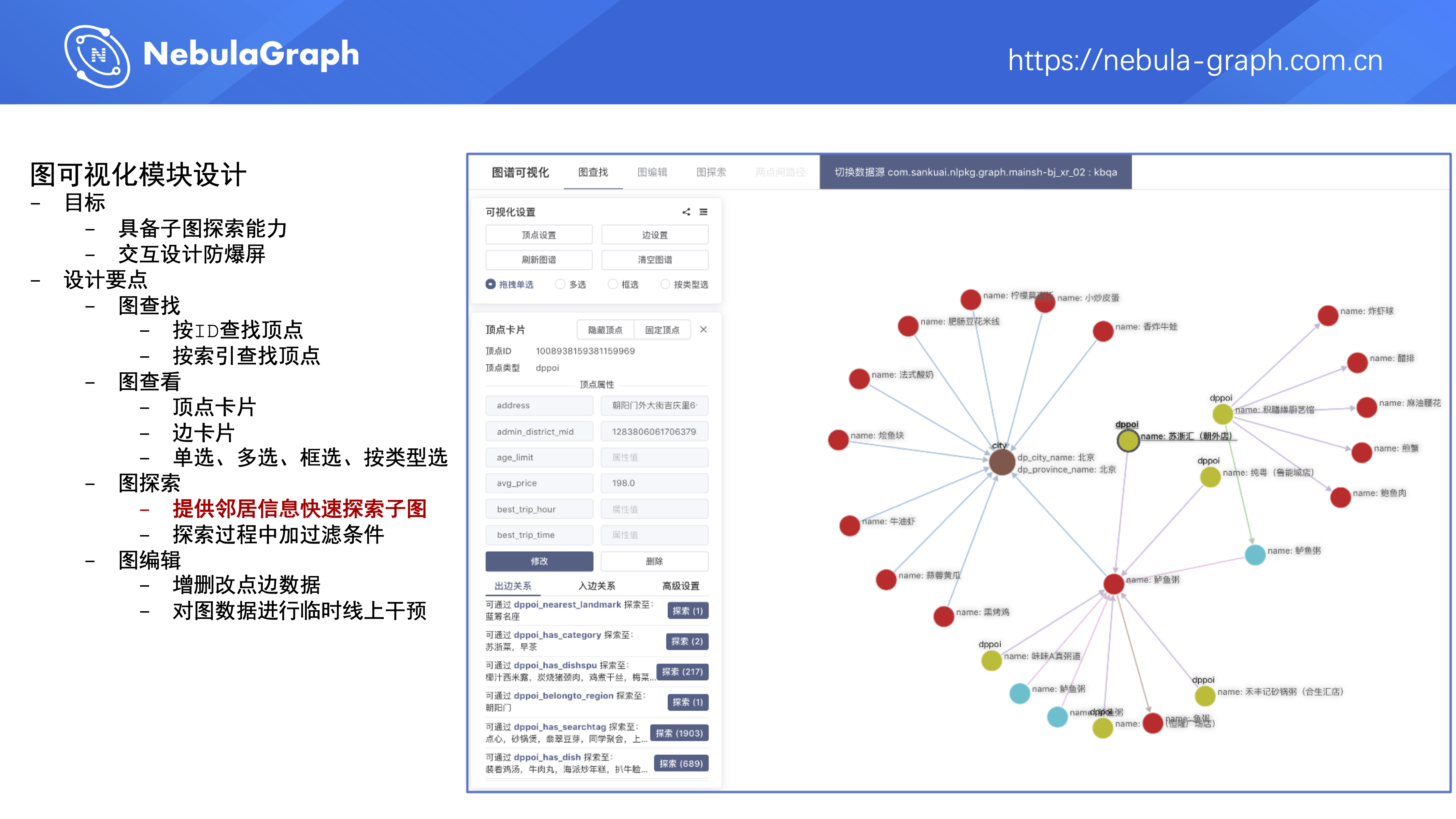
第四个模块是图可视化模块,平台在 2020 年上半年调研了 Nebula Graph 官方的图可视化设计跟一些第三方开源的可视化组件,然后在图数据库平台上增加了通用的图可视化功能,主要是用于解决子图探索问题;当用户在图数据库平台通过可视化组件查看图数据时,能尽量通过恰当的交互设计来避免因为节点过多而引发爆屏。
目前,平台上的可视化模块有下面几个功能。
第一个是通过 ID 或者索引查找顶点。
第二个是能查看顶点和边的卡片(卡片中展示点边属性和属性值),可以单选、多选、框选以及按类型选择顶点。

第三个是图探索,当用户点击某个顶点时,系统会展示它的一跳邻居信息,包括:该顶点有哪些出边?通过这个边它能 Touch 到几个点?该顶点的入边又是什么情况?通过这种一跳信息的展示,用户在平台上探索子图的时候,可快速了解到周边的邻居信息,更快地进行子图探索。在探索过程中,平台也支持对边进行过滤。
第四个是图编辑能力,让平台用户在不熟悉 Nebula Graph 语法的情况下也能增删改点边数据,对线上数据进行临时的干预。
业务实践

下面来介绍下接入我们平台的一些落地项目。
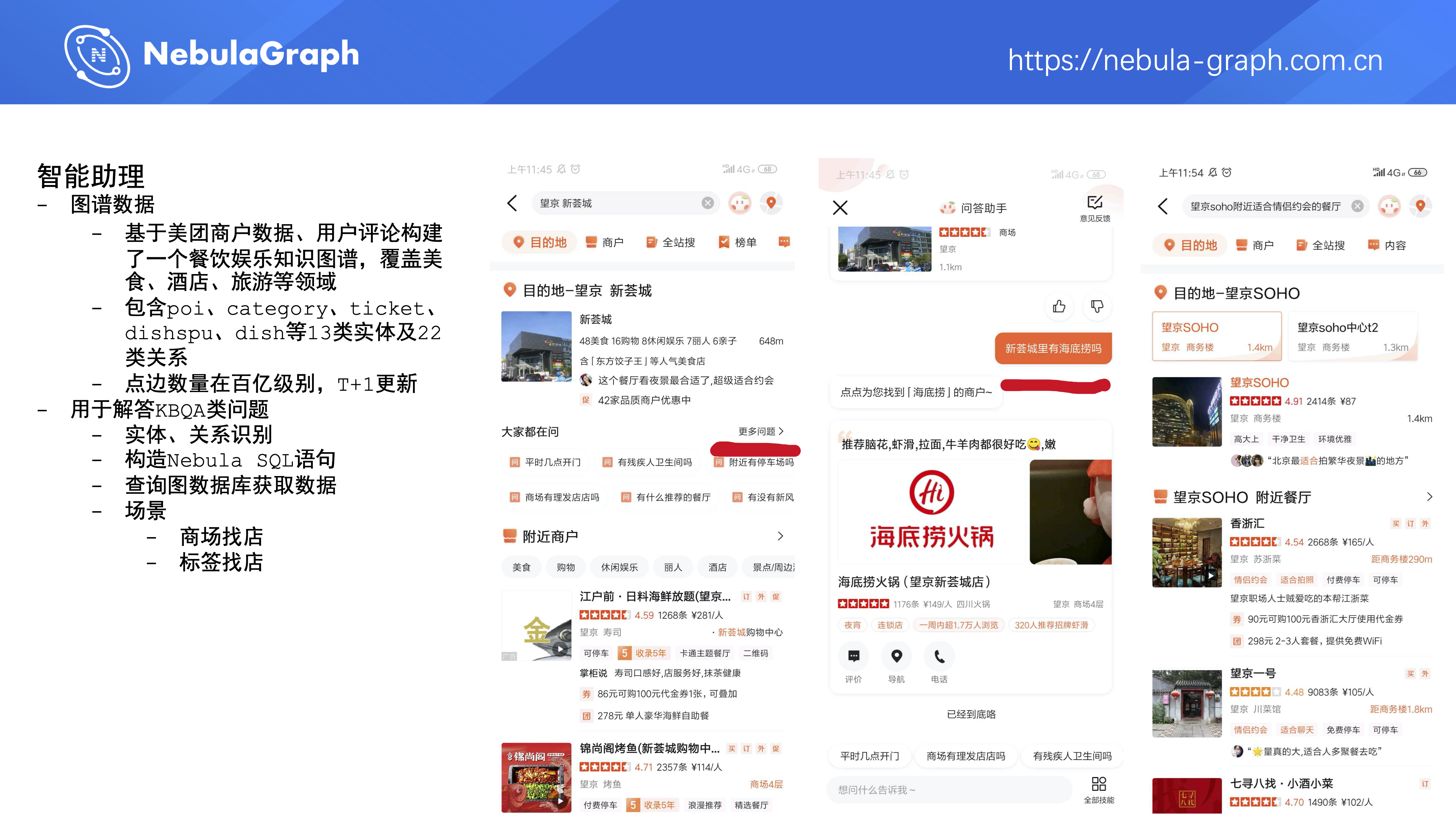
第一个项目是智能助理,它的数据是基于美团商户数据、用户评论构建的餐饮娱乐知识图谱,覆盖美食、酒店、旅游等领域,包含 13 类实体和 22 类关系。目前点边数量大概在百亿级别,数据是 T+1 全量更新,主要用于解决搜索或者智能助理里 KBQA (全称:Knowledge Based Question Answer )类的问题。核心处理流程是通过 NLP 算法识别关系和实体后构造出 Nebula Graph SQL 语句,再到图数据库获取数据。
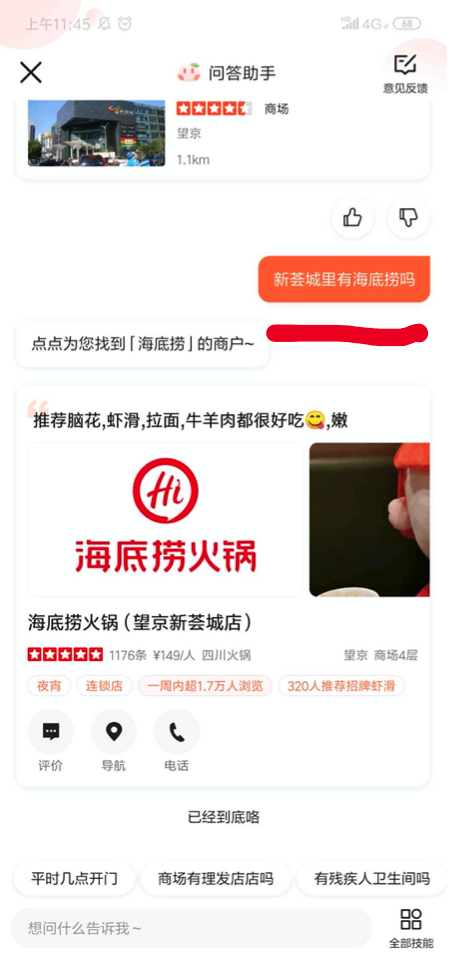
典型的应用场景有商场找店,比如,某个用户想知道望京新荟城这个商场有没有海底捞,智能助理就能快速查出结果告诉用户。
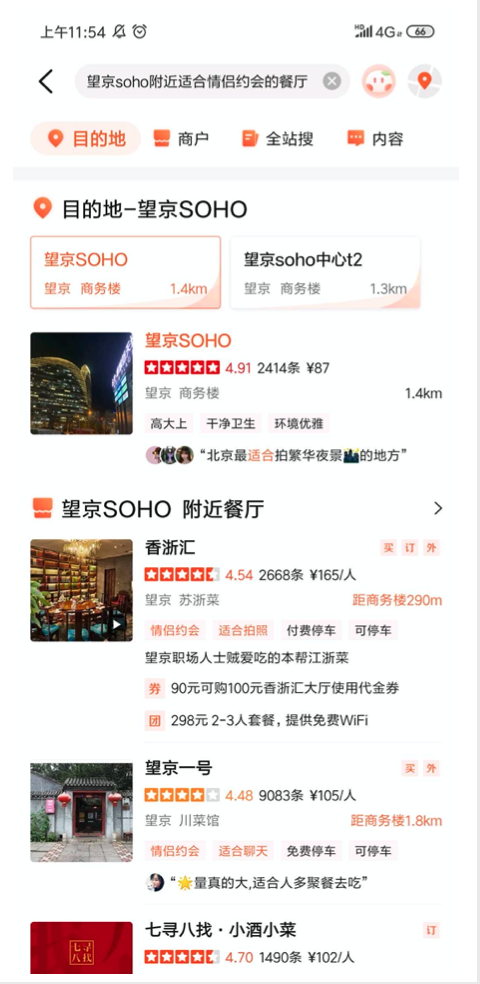
还有一个典型场景是标签找店,想知道望京 SOHO 附近有没有适合情侣约会的餐厅,或者你可以多加几个场景标签,系统都能给你查找出来。
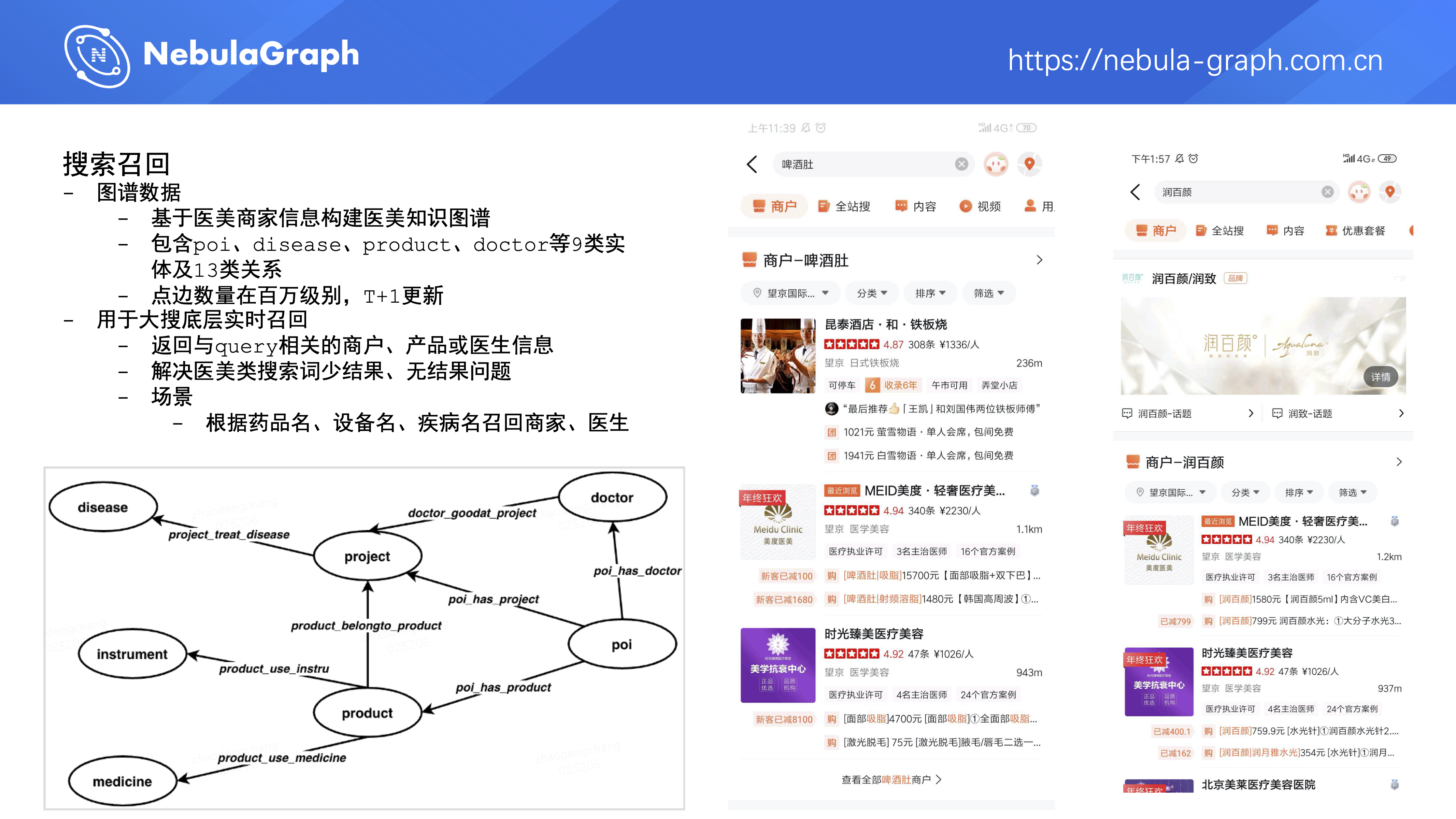
第二个是搜索召回,数据主要是基于医美商家信息构建的医美知识图谱,包含 9 类实体和 13 类关系,点边数量在百万级别,同样也是 T+1 全量更新,主要用于大搜底层实时召回,返回与 query 相关的商户、产品或医生信息,解决医美类搜索词少结果、无结果问题。比如,某个用户搜“啤酒肚”这种症状、或者“润百颜”这类品牌,系统都能给他召回相关的医美门店。
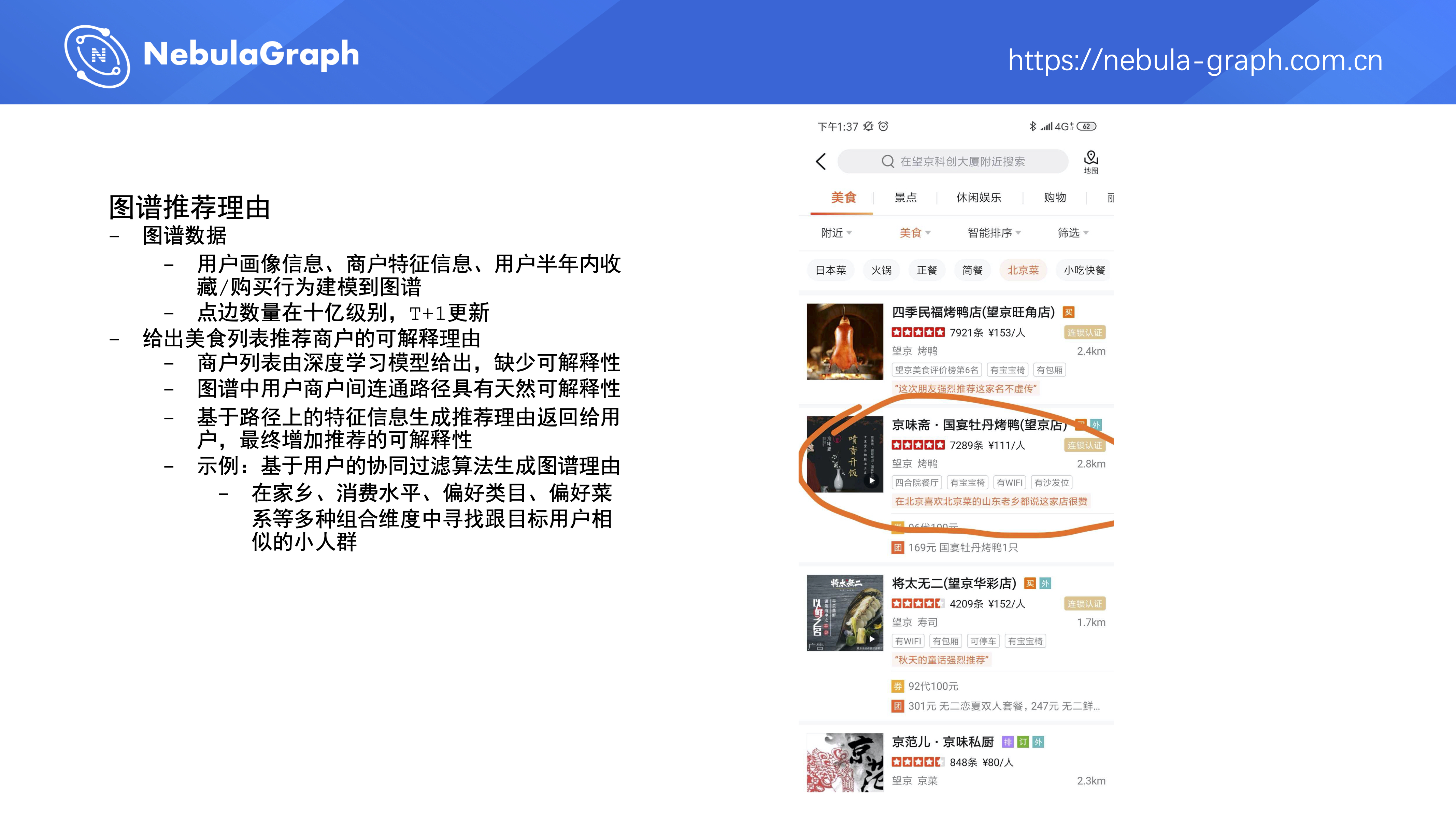
第三个是图谱推荐理由,数据来自用户的画像信息、商户的特征信息、用户半年内收藏 /购买行为,现在的数据量级是 10 亿级别,T+1 全量更新。这个项目的目标是给出美食列表推荐商户的可解释理由。为什么会做这个事呢?现在美团 App 和点评 App 上默认的商户推荐列表是由深度学习模型生成的,但模型并不会给出生成这个列表的理由,缺少可解释性。然而在图谱里用户跟商户之间天然存在多条连通路径,我们希望能选出一条合适路径来生成推荐理由,在 App 界面上展示给用户推荐某家店的原因。比如我们可以基于用户的协同过滤算法来生成推荐理由,在家乡、消费水平、偏好类目、偏好菜系等多个组合维度中找出多条路径,然后给这些路径打分,选出一条分值较高的路径,之后按照特定 pattern 产出推荐理由。通过上述方式,就可以获得在北京喜欢北京菜的山东老乡都说这家店很赞,或者广州老乡都中意他家的正宗北京炸酱面这类理由。
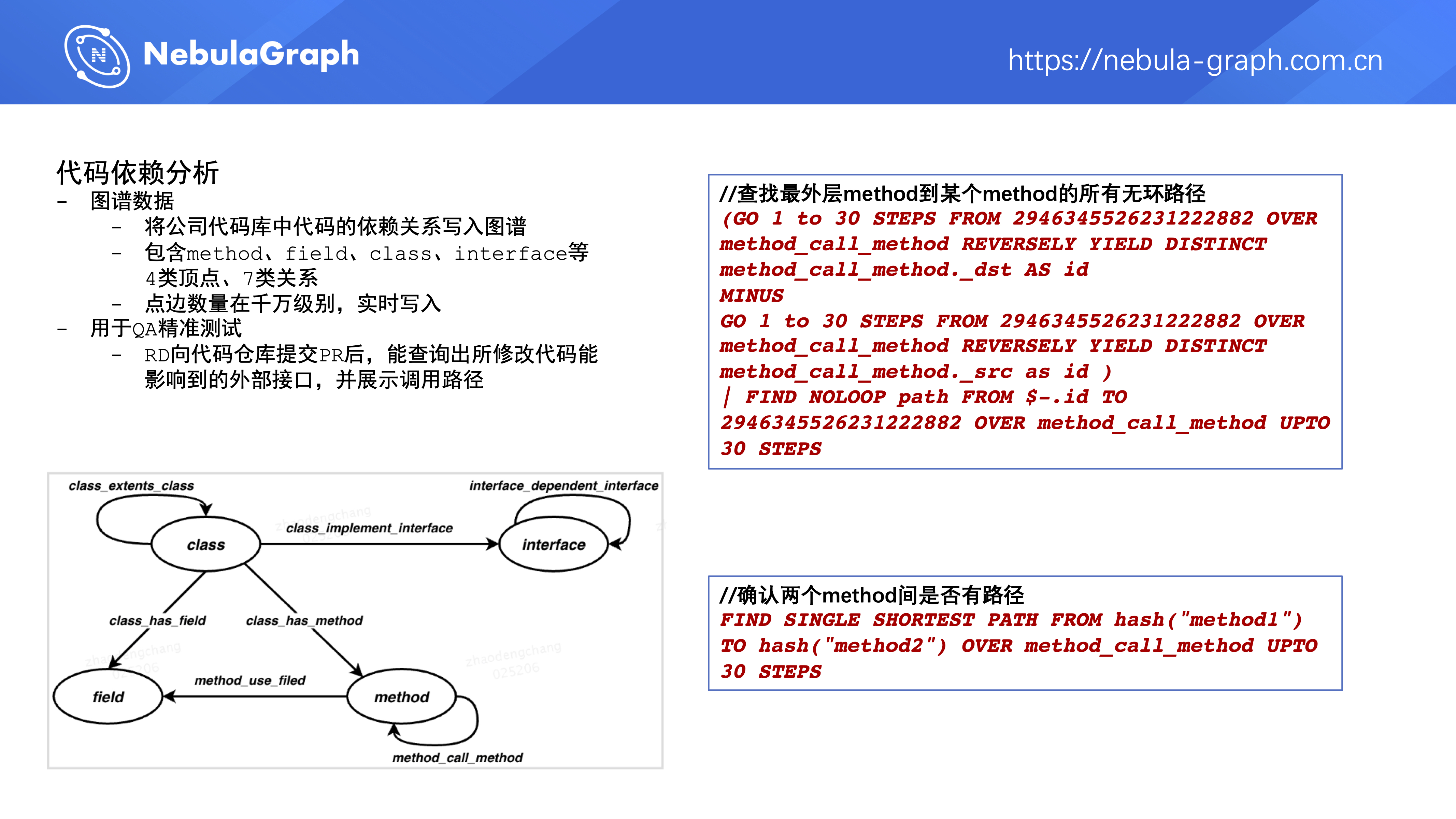
第四个是代码依赖分析,是把公司里的代码库中代码依赖关系写到图数据库。公司代码库里有很多服务代码,这些服务都会有对外提供的接口,这些接口的实现依赖于该服务中某些类的成员函数,这些类的成员函数又依赖了本类的成员变量、成员函数、或者其它类的成员函数,那么它们之间的依赖关系就形成了一张图,我们把这个图写到图数据库里,做什么事呢?
典型场景是 QA 的精准测试,当 RD 完成需求并向公司的代码仓库提交了他的 pr 后,这些更改会实时地写到图数据库中,所以 RD 就能查到他所写的代码影响了哪些外部接口,并且能展示出调用路径来。如果 RD 本来是要改接口 A 的行为,他改了很多东西,但是他可能并不知道他改的东西也会影响到对外接口 B 、C 、D,这时候就可以用代码依赖分析来做个 Check 。
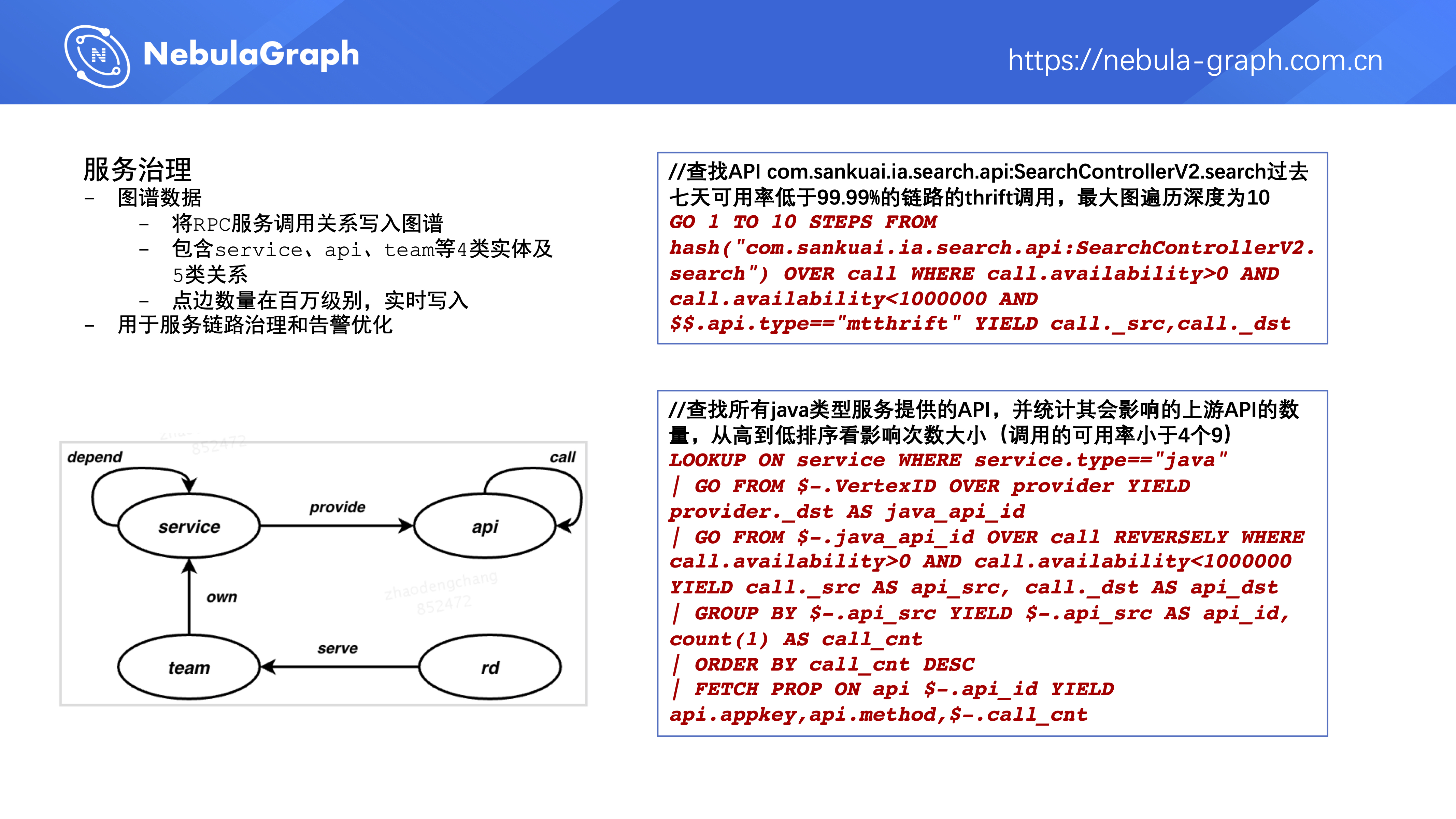
第五个是服务治理,美团内部有几十万个微服务,这些微服务之间存在互相调用关系,这些调用关系形成了一张图。我们把这些调用关系实时写入图数据库里,然后做一些服务链路治理和告警优化工作。
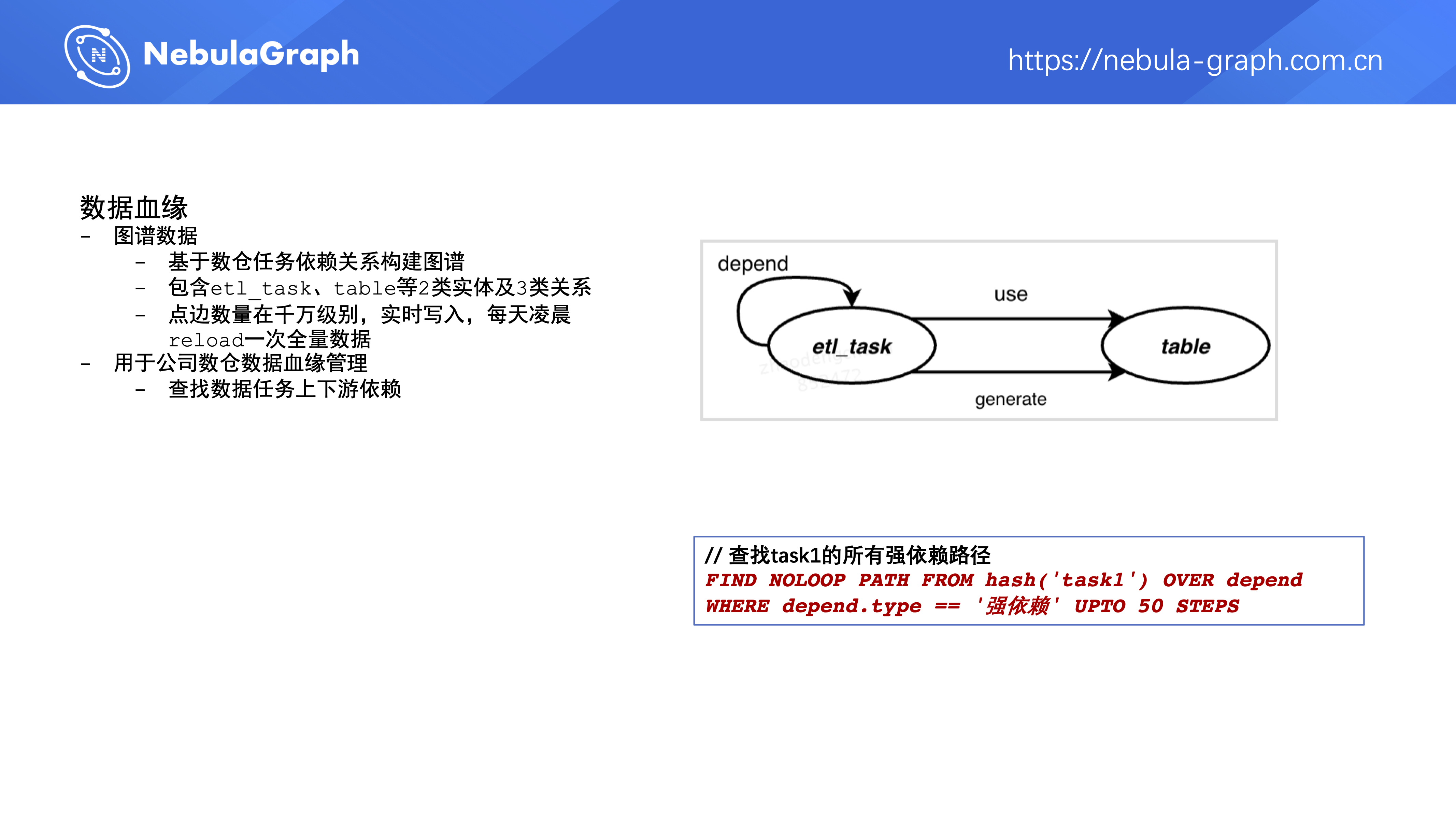
第六个项目是数据血缘,把数仓中 ETL 任务的依赖关系写到了图数据库中,大概是千万级别的数据量级,数据实时写入,每天凌晨做一次全量 reload,主要是用来查找数据任务的上下游依赖。比如说,通过这个 FIND NOLOOP PATH FROM hash('task1') OVER depend WHERE depend.type == '强依赖' UPTO 50 STEPS 语句找出 task1 这个任务的所有强依赖路径。这里,我们针对 Nebula Graph 官方的 FIND PATH 功能做了一些加强,添加了无环路径的检索跟 WHERE 语句过滤。
美团和 Nebula

最后,来介绍下团队对社区的贡献。

为了更好地满足图数据库平台上用户的需求,我们对 Nebula Graph 1.0 的内核做了部分功能的扩充和部分性能的优化,并把相对来说比较通用的功能给 Nebula Graph 社区提了 PR,也向社区公众号投稿了一篇 主流开源分布式图数据库 Benchmark 🔗 。
当然,我们通过 Nebula Graph 解决了公司内的很多业务问题,目前对 Nebula Graph 社区做的贡献还比较少,后续会加强在社区技术共享方面的工作,希望能够培养出越来越多的 Nebula Committer 。
美团图数据库平台的未来规划


未来规划主要有两个方面,第一方面是等 Nebula Graph 2.0 的内核相对稳定后,在我们图数据库平台上适配 Nebula Graph 2.0 内核。第二方面是去挖掘更多的图数据价值。现在美团图数据库平台支持了图数据存储及多跳查询这种基本能力,后续我们打算基于 Nebula Graph 去探索一下图学习、图计算的能力,给平台用户提供更多挖掘图数据价值的功能。
以上为本次美团 NLP 技术专家——赵登昌老师带来的图数据库平台建设方面的分享。
如果你对 [图存储] 、 [图学习] 、 [图计算] 感兴趣,欢迎向赵登昌老师投递简历,投递邮箱: [email protected] 。
喜欢这篇文章?来来来,给我们的 GitHub 点个 star 表鼓励啦~~ 🙇♂️🙇♀️ [手动跪谢]
交流图数据库技术?交个朋友,Nebula Graph 官方小助手微信:NebulaGraphbot 拉你进交流群~~
{kind=link}
 |
1
18258226728 2021-01-20 16:20:23 +08:00
赞一个,整套流程介绍,学习了
|